




Essentially, all the work of C P used the message-passing model
with the application scientist decomposing the problem by hand and
generating C (and sometimes Fortran) plus message-passing code to
express the parallel program. This book is designed to show that this
message-passing model is effective. It gets good performance and
experienced users find it convenient to use as it is the most powerful
approach that can express essentially all problems as long as the
software is suitably embellished-with, if necessary, the
functionality described in Chapters 15, 16, and
17. However, we can regard the success of message passing
for parallel computing as comparable to the success of machine
language programming for conventional machines. This was how
early computers were programmed, and is still used today to
get optimal performance for computational kernels and libraries.
However, the overwhelming majority of lines of sequential code are
developed, not with machine language but with high-level languages
such as Fortran, C, or even higher level object-oriented systems.
There are at least two reasons to seek a higher level approach than
message passing for parallel computing, reasons that are shared by
the machine language analogy.
P used the message-passing model
with the application scientist decomposing the problem by hand and
generating C (and sometimes Fortran) plus message-passing code to
express the parallel program. This book is designed to show that this
message-passing model is effective. It gets good performance and
experienced users find it convenient to use as it is the most powerful
approach that can express essentially all problems as long as the
software is suitably embellished-with, if necessary, the
functionality described in Chapters 15, 16, and
17. However, we can regard the success of message passing
for parallel computing as comparable to the success of machine
language programming for conventional machines. This was how
early computers were programmed, and is still used today to
get optimal performance for computational kernels and libraries.
However, the overwhelming majority of lines of sequential code are
developed, not with machine language but with high-level languages
such as Fortran, C, or even higher level object-oriented systems.
There are at least two reasons to seek a higher level approach than
message passing for parallel computing, reasons that are shared by
the machine language analogy.
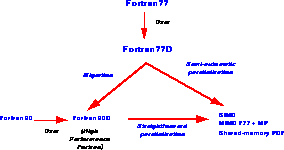
Figure 13.1: The Initial Integrated FortranD Environment
We can illustrate the portability issues with two anecdotes from
C P. Our original (Cosmic Cube and Mark II)
hypercubes did not allow the overlap of communication and calculation.
However, we carefully designed the Mark IIIfp to allow the performance
enhancement offered by this overlap. However, we made little use of
this hardware feature because all our codes, algorithms and software
support (CrOS) had been developed for the original hardware. Even the
``Marine Corps'' of C
P. Our original (Cosmic Cube and Mark II)
hypercubes did not allow the overlap of communication and calculation.
However, we carefully designed the Mark IIIfp to allow the performance
enhancement offered by this overlap. However, we made little use of
this hardware feature because all our codes, algorithms and software
support (CrOS) had been developed for the original hardware. Even the
``Marine Corps'' of C P was not willing to recode applications and
systems software to gain the extra performance. Our software did port
between MIMD machines as they evolved and in this sense message passing
is portable. However, the ``optimal'' message-passing implementation
is hardware dependent and nonportable. The goal of higher level
software systems is to rely on compilers and runtime
systems to provide such optimization. As a second anecdote, we note
that C
P was not willing to recode applications and
systems software to gain the extra performance. Our software did port
between MIMD machines as they evolved and in this sense message passing
is portable. However, the ``optimal'' message-passing implementation
is hardware dependent and nonportable. The goal of higher level
software systems is to rely on compilers and runtime
systems to provide such optimization. As a second anecdote, we note
that C P shared a
P shared a  CM-2 with Argonne National
Laboratory. C
CM-2 with Argonne National
Laboratory. C P's use of this was disappointing even though several
of our applications, such as QCD in Chapter 4, were very
suitable for this SIMD architecture. We had excellent parallel (QCD)
codes, which we ran in production, but these were written with message
passing and this could not run on the CM-2. We were not willing to
recode in CMFortran to use the SIMD machine for this problem.
P's use of this was disappointing even though several
of our applications, such as QCD in Chapter 4, were very
suitable for this SIMD architecture. We had excellent parallel (QCD)
codes, which we ran in production, but these were written with message
passing and this could not run on the CM-2. We were not willing to
recode in CMFortran to use the SIMD machine for this problem.
C P was correct to concentrate on message passing on its MIMD
machines; this is the only way to good performance on most
(excepting the CM-5) MIMD machines even in 1992-ten years after we
started. However, the enduring lesson of C
P was correct to concentrate on message passing on its MIMD
machines; this is the only way to good performance on most
(excepting the CM-5) MIMD machines even in 1992-ten years after we
started. However, the enduring lesson of C P was that ``Parallel
Computing Works.'' There is no reason that our particular software
approach should endure in the same fashion. Rather, we wish to embody
the lessons of C
P was that ``Parallel
Computing Works.'' There is no reason that our particular software
approach should endure in the same fashion. Rather, we wish to embody
the lessons of C P's work into better and higher level software
systems.
P's work into better and higher level software
systems.

Table 13.1: Reasons to build parallel languages on top of existing
languages-especially Fortran, C, C++
In 1987, Fox and Kennedy shared a crowded Olympus Airways flight from Athens to New York. Their conversations were key in establishing the collaboration on FortranD [Bozkus:93a;93b], [Choudhary:92c;92d;92e],
[Fox:91e], [Ponnusamy:92c]. This combined the parallel
compiler expertise of Kennedy [Callahan:88e], [Hiranandani:91a;91b],
with C P's wisdom in
practical use of parallel machines. Again, Fox's move to Syracuse
allowed him to compare the successes of CMFortran on
the SIMD CM-2 with those of message passing on the C
P's wisdom in
practical use of parallel machines. Again, Fox's move to Syracuse
allowed him to compare the successes of CMFortran on
the SIMD CM-2 with those of message passing on the C P MIMD
emporium. He concluded that one could use high-level data-parallel
Fortran for both SIMD and MIMD machines. This evolved FortranD from
its initial Fortran 77D implementation to include a Fortran 90D version
[Wu:92a], illustrated in Figure 13.1.
Section 13.3 describes some of the experiments leading to this
realization. We will not describe data-parallel Fortran in detail
because the situation is still quite fluid and this is an area that has
grown spectacularly since 1990 when C
P MIMD
emporium. He concluded that one could use high-level data-parallel
Fortran for both SIMD and MIMD machines. This evolved FortranD from
its initial Fortran 77D implementation to include a Fortran 90D version
[Wu:92a], illustrated in Figure 13.1.
Section 13.3 describes some of the experiments leading to this
realization. We will not describe data-parallel Fortran in detail
because the situation is still quite fluid and this is an area that has
grown spectacularly since 1990 when C P finished its project.
P finished its project.

Table 13.2: Features of the Fortran(C) Plus Message-Passing Paradigm
Section 13.2 describes a prototype software tool built at Caltech and Rice by Vas Balasundaram and Uli Kremer to enable users to experiment with different decompositions. This was a component of the FortranD project set up as part of the NSF Center for Research in Parallel Computation (CRPC). FortranD was set up as a scalable language, that is,
``We may need to rewrite our code for a parallel machine, but the resulting scalable (FortranD) code should run with high efficiency on `all' current and future anticipated machines.''
Many new parallel languages have been proposed-OCCAM is
a well known example [Pritchard:91a]-but none are ``compelling''
that is, they do not solve enough parallel issues to warrant adoption.
Thus, the recent trend has been to adapt existing languages such as
Fortran [Brandes:92a], [Callahan:88e], [Chapman:92a],
[Chen:92b], [Gerndt:90a], [Merlin:92a], [Zima:88a],
C++ [Bodin:91a], C [Hamel:92a],
[Hatcher:91a;91b], and Lisp. The latter is
illustrated by the successful *Lisp, parallel Lisp implementation
available on the CM-1, 2, and 5. Table 13.1 summarizes some
of the issues involved in choosing to adopt a new language rather than
modifying an old one. Table 13.2 summarizes the
message-passing approach and why we might choose to replace it by a
higher level system, such as data-parallel C or Fortran as summarized
in Table 13.3. We were impressed by the C language
offered on the CM-2; Section 13.6 describes an early experiment
to develop a loosely synchronous version of this. We should probably
have explored this more thoroughly, although at the time we did not
perceive this as our mission and realized this project would require
major resources to develop a system with good performance. Indeed, the
performance of the early CM-2 C
language
offered on the CM-2; Section 13.6 describes an early experiment
to develop a loosely synchronous version of this. We should probably
have explored this more thoroughly, although at the time we did not
perceive this as our mission and realized this project would require
major resources to develop a system with good performance. Indeed, the
performance of the early CM-2 C compiler was poor and this also
discouraged us. Quinn and Hatcher implemented a similar but more
restrictive C
compiler was poor and this also
discouraged us. Quinn and Hatcher implemented a similar but more
restrictive C MIMD compiler [Hatcher:91a]. ASPAR, in
Section 13.5, had similar goals to Fortran 77D, although it was
targeted more as a migration tool than an efficient complete compiler.
MIMD compiler [Hatcher:91a]. ASPAR, in
Section 13.5, had similar goals to Fortran 77D, although it was
targeted more as a migration tool than an efficient complete compiler.

Table 13.3: Issues in Data-Parallel Fortran Programming Paradigm
FortranD extends Fortran with a set of directives [Fox:91e], which
help the compiler produce good code on a parallel machine. These
directives include those specifying the decomposition of the data-parallel
arrays onto the target hardware. The language includes forms of
parallel loop (Forall and DO independent) for which
parallelization can be asserted without a difficult dependence
analysis. The run time library implements optimized parallel functions
operating on the data-parallel arrays. Fortran 90D also includes the
parallelism implied by the explicit array notation, for example, if
A, B, and C are arrays of the same size, A=B+C is executed in
parallel. This CRPC research was based in important ways on the
research of C P. Further during 1992, an informal forum
representing all the major players in the parallel computing arena
agreed on a new industry-standard language, High Performance
Fortran or HPF
[Kennedy:93a]. This embodies all the essential ideas of
FortranD-including the full Fortran 90 syntax. We have modified
FortranD so that HPF is a subset of FortranD. The CRPC FortranD
project continues as a research compiler to investigate extensions of
HPF to handle more general problems and unsolved issues such as
parallel I/O [Bordawekar:93a], [Rosario:93a]. We
expect that data-parallel languages should be able to eventually
express nearly all loosely synchronous problems, that is, the vast
majority of scientific and engineering computations.
P. Further during 1992, an informal forum
representing all the major players in the parallel computing arena
agreed on a new industry-standard language, High Performance
Fortran or HPF
[Kennedy:93a]. This embodies all the essential ideas of
FortranD-including the full Fortran 90 syntax. We have modified
FortranD so that HPF is a subset of FortranD. The CRPC FortranD
project continues as a research compiler to investigate extensions of
HPF to handle more general problems and unsolved issues such as
parallel I/O [Bordawekar:93a], [Rosario:93a]. We
expect that data-parallel languages should be able to eventually
express nearly all loosely synchronous problems, that is, the vast
majority of scientific and engineering computations.
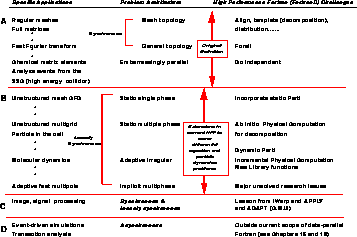
Table 13.4: High Performance Fortran (HPF) and its extensions
The scope of HPF and FortranD is summarized in Table 13.4. Table 13.4(a) roughly covers both the synchronous and embarrassingly parallel calculations of Chapters 4, 6, 7, and 8. Note that we include computations such as the Kuppermann and McKoy chemical reaction problems in Chapter 8, which mix the synchronous and embarrassingly parallel classes. The original FortranD [Fox:91e] and the initial HPF language [Kennedy:93a] should be able to express these two problem classes in such a way that the compiler will get good performance on MIMD and, for synchronous problems, SIMD machines [Choudhary:92d;92e]. Table 13.4(b) covers the loosely synchronous problems of Chapters 9 and 12, which need HPF extensions to express the irregular structure. We intend to incorporate the ideas of PARTI [Berryman:91a], [Saltz:91b] into FortranD as a prototype of an extended HPF that could handle loosely synchronous problems. The difficult applications in Sections 12.4, 12.5, 12.7, and 12.8 have a hierarchical tree structure that is not easy to express [Bhatt:92a], [Blelloch:92a], [Mou:90a], [Singh:92a]. Table 13.4(c) indicates that we have not yet studied HPF and FortranD for signal processing applications, although the iWarp group at Carnegie Mellon University has developed high level languages APPLY and ADAPT for this problem class [Webb:92a]. Table 13.4(d) notes that we cannot express in FortranD and HPF the difficult asynchronous applications introduced in Chapter 14.
We expect this study and implementation of data-parallel languages to be a growing and critical area of parallel computing.
In Section 13.7, we contrast hierarchical and distributed memory systems. Both require data locality and we expect that data parallel languages such as High Performance Fortran will be able to use the HPF directives to improve performance of sequential machines by exploiting the cache and other levels of memory hierarchy better.