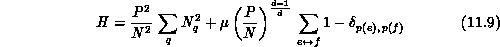We wish to distribute the elements among the processors of the machine to minimize both load imbalance (one processor having more elements than another) and communication between elements.
Our approach here is to write down a cost function which is minimized when the total running time of the code is minimized and is reasonably simple and independent of the details of the code. We then minimize this cost function and distribute the elements accordingly.
The load-balancing problem [Fox:88a;88mm], may be stated as a graph-coloring problem: Given an undirected graph of N nodes (finite elements), color these nodes with P colors (processors) to minimize a cost function H which is related to the time taken to execute the program for a given coloring. For DIME applications, it is the finite elements which are to be distributed among the processors, so the graph to be colored is actually the dual graph to the mesh, where each graph node corresponds to an element of the mesh and has (if it is not at a boundary) three neighbors.
We may construct the cost function as the sum of a part that minimizes load imbalance and one that minimizes communication:\
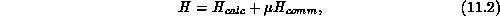
where  is the part of the cost function which is minimized when
each processor has equal work,
is the part of the cost function which is minimized when
each processor has equal work,  is minimal when communication time
is minimized, and
is minimal when communication time
is minimized, and 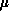 is a parameter expressing the balance between the
two, with
is a parameter expressing the balance between the
two, with 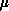 related to the number c discussed above. If
related to the number c discussed above. If  and
and 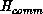 were proportional to the times taken for calculation and
communication, then
were proportional to the times taken for calculation and
communication, then  should be inversely proportional to c. For
programs with a great deal of calculation compared to communication,
should be inversely proportional to c. For
programs with a great deal of calculation compared to communication,
 should be small, and vice versa.
should be small, and vice versa.
As 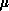 is increased, the number of processors in use will decrease until
eventually the communication is so costly that the entire calculation must be
done on a single processor.
is increased, the number of processors in use will decrease until
eventually the communication is so costly that the entire calculation must be
done on a single processor.
Let e, f,  label the nodes of the graph, and
label the nodes of the graph, and  be the
color (or processor assignment) of graph node e. Then the number of graph
nodes of color q is:\
be the
color (or processor assignment) of graph node e. Then the number of graph
nodes of color q is:\
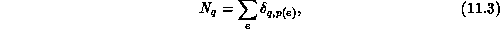
and 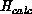 is proportional to the maximum value of
is proportional to the maximum value of 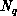 , because the
whole calculation runs at the speed of the slowest processor, and the slowest
processor is the one with the most graph nodes. This ignores node and
link (node-to-node communication) contention, which contribute to idle
time.
, because the
whole calculation runs at the speed of the slowest processor, and the slowest
processor is the one with the most graph nodes. This ignores node and
link (node-to-node communication) contention, which contribute to idle
time.
The formulation as a maximum of 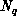 is, however, not satisfactory
when a perturbation is added to the cost function, such as that from
the communication cost function. If, for example, we were to add a
linear forcing term proportional to
is, however, not satisfactory
when a perturbation is added to the cost function, such as that from
the communication cost function. If, for example, we were to add a
linear forcing term proportional to 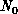 , the cost function would be:\
, the cost function would be:\
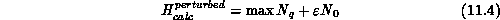
and the minimum of this perturbed cost function is either 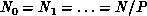 if
if  is less than
is less than  , or
, or 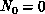 ,
,
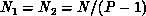 if
if  is larger than this. This
discontinuous behavior as a result of perturbations is undesirable, so
we use a sum of squares instead, whose minima change smoothly with the
magnitude of a perturbation:\
is larger than this. This
discontinuous behavior as a result of perturbations is undesirable, so
we use a sum of squares instead, whose minima change smoothly with the
magnitude of a perturbation:\
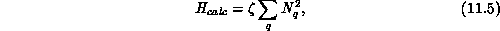
where  is a scaling constant to be determined.
is a scaling constant to be determined.
We now consider the communication part of the cost function. Let us define the matrix

which is the amount of communication between processors q and
r, and the notation  means that the graph nodes
e and f are connected by an edge of the graph.
means that the graph nodes
e and f are connected by an edge of the graph.
The cost of communication from processors q to r depends on the machine architecture; for some parallel machines it may be possible to write down this metric explicitly. For example, with the early hypercubes, the cost is the number of bits which are different in the binary representations of the processor numbers q and r. The metric may also depend on the message-passing software, or even on the activities of other users for a shared machine. A truly portable load balancer would have no option but to send sample messages around and measure the machine metric, then distribute the graph appropriately. In this book, however, we shall avoid the question of the machine metric by simply assuming that all pairs of processors are equally far apart, except of course a processor may communicate with itself at no cost.
The cost of sending the quantity  of data also depends on the
programming: the cost will be much less if it is possible for the
of data also depends on the
programming: the cost will be much less if it is possible for the
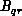 messages to be bundled together and sent as one, rather
than separately. The major problem is latency: The
cost to send a message in any distributed system is the sum of an
initial fixed price and one proportional to the size of the
message. This is also the case for the pricing of telephone calls,
freight shipping, mail service, and many other examples from the
everyday world. If the message is large enough, we may ignore
latency: For the nCUBE used in Section 11.1.7 of this book,
latency may be ignored if the message is longer than a hundred bytes or
so. In the tests of Section 11.1.7, most of the messages are
indeed long enough to neglect latency, though there is certainly
further work needed on load balancing in the presence of this important
effect. We also ignore blocking (idling) due to needed resources
being unavailable due to contention.
messages to be bundled together and sent as one, rather
than separately. The major problem is latency: The
cost to send a message in any distributed system is the sum of an
initial fixed price and one proportional to the size of the
message. This is also the case for the pricing of telephone calls,
freight shipping, mail service, and many other examples from the
everyday world. If the message is large enough, we may ignore
latency: For the nCUBE used in Section 11.1.7 of this book,
latency may be ignored if the message is longer than a hundred bytes or
so. In the tests of Section 11.1.7, most of the messages are
indeed long enough to neglect latency, though there is certainly
further work needed on load balancing in the presence of this important
effect. We also ignore blocking (idling) due to needed resources
being unavailable due to contention.
The result of this discussion is that we shall assume that the cost of
communicating the quantity 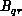 of data is proportional to
of data is proportional to 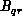 ,
unless q=r, in which case the cost is zero. This is a good
assumption on many new machines, such as the Intel Touchstone series.
,
unless q=r, in which case the cost is zero. This is a good
assumption on many new machines, such as the Intel Touchstone series.
We shall now make the assumption that the total communication cost is the sum of the individual communications between processors:\

where  is a constant to be determined. Notice that any
overlap between calculation and communication is ignored. Here, we
have ignored ``global'' contributions to
is a constant to be determined. Notice that any
overlap between calculation and communication is ignored. Here, we
have ignored ``global'' contributions to  , such as
collective communication (global sums or reductions) mentioned in
Section 11.1.1.
, such as
collective communication (global sums or reductions) mentioned in
Section 11.1.1.
Substituting the expression for 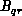 , the expression for the load balance
cost function simplifies to
, the expression for the load balance
cost function simplifies to
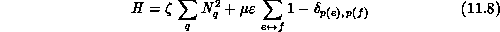
The assumptions made to derive this cost function are significant. The most serious deviation from reality is neglecting the parallelism of communication, so that a minimum of this cost function may have grossly unbalanced communication loads. This turns out not to be the case, however, because when the mesh is equally balanced, there is a lower limit to the amount of boundary, analogous to a bubble having minimal surface area for fixed volume; if we then minimize the sum of surface areas for a set of bubbles of equal volumes, each surface must be minimized and equal.
We may now choose the scaling constants 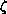 and
and  . A
convenient choice is such that the optimal
. A
convenient choice is such that the optimal 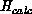 and
and 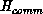 have contributions of about unit size from each processor; the form
of the scaling constant
have contributions of about unit size from each processor; the form
of the scaling constant  is because the surface area of a
compact shape in d dimensions varies as the d-1 power of the size,
while volume varies as the d power. The final form for H is
is because the surface area of a
compact shape in d dimensions varies as the d-1 power of the size,
while volume varies as the d power. The final form for H is
where d is the dimensionality of the mesh from which the graph came.
The formalism of this section has a simple physical interpretation
[Fox:86a;88kk;88mm;88tt;88uu], which we introduce here and discuss further in Section 11.2. The data points (tasks) to be distributed can be thought of as particles moving around in the discrete space formed by the processors. This physical system is controlled by the Hamiltonian (energy function) given in Equation 11.9. The two terms in the Hamiltonian have simple physical meanings illustrated in Figure 11.3. The first term in Equation 11.9 ensures equal work per node and is a short-range repulsive force trying to push particles away if they land in the same node. The second term in Equation 11.9 is a long-range attractive force which links ``particles'' (data points) which communicate with each other. This force tries to pull particles together (into the same node) with a strength proportional to the information needed to be communicated between them. In general, this communication force depends on the architecture of the interconnect of the parallel machine, although Equation 11.9 has assumed a simple form for this. The analogy is preserved in general with the MPP interconnect architecture translating into a topology for the discrete space formed by the processors in the analogy. This topology implies a distance dependence force for the communication term in H. We can also extend the discussion to include the cost of moving data between processors to rebalance a dynamically changing problem. This migration cost becomes a third force attracting each particle to the processor in which it currently resides. Figure 11.3 illustrates these three forces.
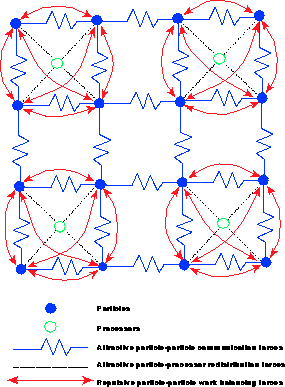
Figure: Sixteen Data Points Distributed Optimally on Four Processors,
Illustrating the Physical Analogy of Section 11.3.
We take a simple two-dimensional mesh connection for the particles.
Note that the load-balancing problem becomes that of finding the equilibrium state of a system of particles with a ``conflict'' between short-range repulsive (hardcore) and long-range attractive forces. This scenario is qualitatively similar to classical atomic physics problems and leads one to expect that the physically based optimization methods could be effective. This physical analogy is extended in Section 11.2 where we show that the physical system exhibits effects that can be associated with temperature and phase transitions. We also indicate how it needs to be extended for problems with microscopic structure in their temporal properties.