




Next: Storage and Computational Costs.
Up: Jacobi-Davidson Methods G. Sleijpen
Previous: Basic Theory
Contents
Index
The basic form of the Jacobi-Davidson algorithm is given in
Algorithm 4.13. Later, we will describe more sophisticated variants
with restart and other strategies.
In each iteration of this algorithm an approximated eigenpair
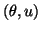 for the eigenpair of the Hermitian matrix
for the eigenpair of the Hermitian matrix 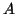 ,
corresponding to the largest eigenvalue of , is computed. The
iteration process is terminated as soon as the norm of the residual
,
corresponding to the largest eigenvalue of , is computed. The
iteration process is terminated as soon as the norm of the residual
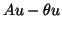 is below a given threshold
is below a given threshold 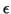 .
.

To apply this algorithm we need to specify
a starting vector 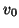 and a tolerance .
On completion an approximation for the largest eigenvalue
and a tolerance .
On completion an approximation for the largest eigenvalue
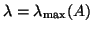 and its corresponding eigenvector
and its corresponding eigenvector
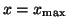 is delivered.
The computed eigenpair
is delivered.
The computed eigenpair
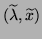 satisfies
satisfies
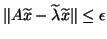 .
.
We will now describe some implementation details, referring to the
respective phases in Algorithm 4.13.
- (1)
- This is the initialization phase of the process. The search subspace is
expanded in each iteration by a vector
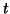 , and we start this process with a given
vector
, and we start this process with a given
vector 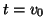 . Ideally, this vector should have a significant component in the
direction of the wanted eigenvector. Unless one has some idea of the
wanted eigenvector, it may be a good idea to start with a random vector.
This gives some confidence that the wanted
eigenvector has a nonzero component in the starting vector, which is
necessary for detection of the eigenvector.
. Ideally, this vector should have a significant component in the
direction of the wanted eigenvector. Unless one has some idea of the
wanted eigenvector, it may be a good idea to start with a random vector.
This gives some confidence that the wanted
eigenvector has a nonzero component in the starting vector, which is
necessary for detection of the eigenvector.
- (3)-(5)
- This represents the modified Gram-Schmidt process
for the orthogonalization of the new vector
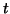 with respect to the set
with respect to the set
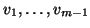 . If
. If 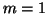 , this is an empty loop. Let
, this is an empty loop. Let 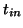 represent the vector before the start of the orthogonalization, and
represent the vector before the start of the orthogonalization, and
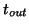 the vector that results at completion of phase (3)-(5). It is
advisable (see [96]) to repeat the Gram-Schmidt process one
time if
the vector that results at completion of phase (3)-(5). It is
advisable (see [96]) to repeat the Gram-Schmidt process one
time if
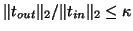 , where
, where 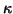 is a
modest constant, say
is a
modest constant, say 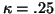 . This guarantees that the loss of
orthogonality is restricted to
. This guarantees that the loss of
orthogonality is restricted to 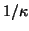 times machine precision, in a
relative sense. The template for this modified Gram-Schmidt
orthogonalization with iterative refinement is given in
Algorithm 4.14.
times machine precision, in a
relative sense. The template for this modified Gram-Schmidt
orthogonalization with iterative refinement is given in
Algorithm 4.14.
- (7)-(9)
- In this phase, computation of the
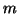 th column of the upper triangular part of the
matrix
th column of the upper triangular part of the
matrix
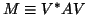 occurs. The matrix
occurs. The matrix 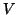 denotes
the
denotes
the 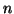 by matrix with columns
by matrix with columns 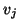 ,
, 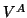 likewise.
likewise.
- (10)
- Computing the largest eigenpair of the
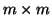 Hermitian matrix
Hermitian matrix 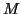 , with
elements
, with
elements 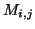 in its upper triangular part, can be done with the
appropriate routines from LAPACK (see §4.2).
in its upper triangular part, can be done with the
appropriate routines from LAPACK (see §4.2).
- (12)
- The vector
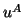 may either be updated as described here or
recomputed as
may either be updated as described here or
recomputed as
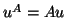 , depending on which is cheapest. The choice
is between an -fold update and another multiplication with ; if
has fewer than
, depending on which is cheapest. The choice
is between an -fold update and another multiplication with ; if
has fewer than 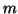 nonzero elements on average per row, the
computation via
nonzero elements on average per row, the
computation via 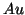 is preferable. If is computed
as , it is not necessary to store the vectors
is preferable. If is computed
as , it is not necessary to store the vectors 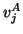 .
.
- (14)
- The algorithm is terminated if
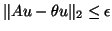 . In
that case has an eigenvalue
. In
that case has an eigenvalue 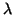 for which
for which
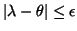 . For the corresponding normalized eigenvector
there is a similar bound on the angle, provided that is simple
and well separated from the other eigenvalues of .
That case leads also to a sharper bound for
; see (4.5) or §4.8.
. For the corresponding normalized eigenvector
there is a similar bound on the angle, provided that is simple
and well separated from the other eigenvalues of .
That case leads also to a sharper bound for
; see (4.5) or §4.8.
Convergence to a
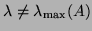 may take place, but is in general
unlikely. It happens, for instance, if
may take place, but is in general
unlikely. It happens, for instance, if
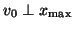 , or
if the selected
, or
if the selected 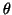 is very close to an eigenvalue
.
This may happen for any iterative solver, in particular if
is taken not small enough (say, larger than
the square root of machine precision).
is very close to an eigenvalue
.
This may happen for any iterative solver, in particular if
is taken not small enough (say, larger than
the square root of machine precision).
- (15)
- The approximate solution for the expansion vector can be computed
with a Krylov solver, for instance, MINRES, or with SYMMLQ. With left-
or right-preconditioning one has to select a Krylov solver for
unsymmetric systems (like GMRES, CGS, or Bi-CGSTAB), since the
preconditioned operator is in general not symmetric. A template for the
approximate solution, with a left-preconditioned Krylov subspace
method of choice, is given in Algorithm 4.15.
The right preconditioned case, which is slightly more expensive, is
covered by the template in Algorithm 4.16.
For iterative Krylov
subspace solvers see [41]. The approximate solution has to be
orthogonal to
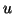 , but that is automatically the case with Krylov
solvers if one starts with an initial guess orthogonal to , for
instance,
, but that is automatically the case with Krylov
solvers if one starts with an initial guess orthogonal to , for
instance, 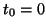 . In most cases it is not necessary to solve the
correction equation to high precision; a relative precision of
. In most cases it is not necessary to solve the
correction equation to high precision; a relative precision of 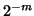 in the th iteration seems to suffice. It is advisable to put a limit
to the number of iteration steps for the iterative solver.
in the th iteration seems to suffice. It is advisable to put a limit
to the number of iteration steps for the iterative solver.
Davidson
[99] suggested taking
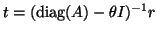 ,
but in this case is not orthogonal with respect to . Moreover,
for diagonal matrices this choice leads to stagnation, which is an
illustration of the problems in this approach.
,
but in this case is not orthogonal with respect to . Moreover,
for diagonal matrices this choice leads to stagnation, which is an
illustration of the problems in this approach.
In order to restrict storage, the algorithm can be terminated at some
appropriate value
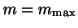 and restarted with
and restarted with 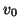 as the latest
value of . We will describe a variant of the Jacobi-Davidson
algorithm with a more sophisticated restart strategy in
§4.7.3.
as the latest
value of . We will describe a variant of the Jacobi-Davidson
algorithm with a more sophisticated restart strategy in
§4.7.3.
Note that most of the computationally intensive operations, i.e., those
operations the cost of which is proportional to , can easily be parallelized.
Also, the multiple vector updates can be
performed by the appropriate Level 2 BLAS routines (see §10.2).
In the coming subsections we will describe more sophisticated variants
of the Jacobi-Davidson algorithm. In §4.7.3 we will
introduce a variant that allows for restarts, which is convenient
if one wants to keep the dimensions of the involved subspaces limited.
This variant is also suitable for a restart after an eigenpair has been
discovered, in order to locate the next eigenpair. The technique is based
on deflation. The resulting algorithm is designed for the computation of
a few of the largest or smallest eigenvalues of a given matrix.
In §4.7.4 we will describe a variant of the Jacobi-Davidson method
that is suitable for the computation of interior eigenvalues of .



Subsections
Next: Storage and Computational Costs.
Up: Jacobi-Davidson Methods G. Sleijpen
Previous: Basic Theory
Contents
Index
Susan Blackford
2000-11-20