Figures ![]() (a) and
(a) and ![]() (b)
show the bandwidth obtained between two nodes of the Intel Paragon for
(b)
show the bandwidth obtained between two nodes of the Intel Paragon for
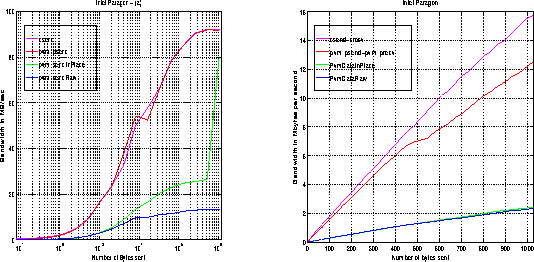
Figure: Bandwidth on the Intel Paragon: PVM3 - NX
As expected, the native message-passing library is the
most efficient, with an asymptotic bandwidth of 72 Mbytes/sec.
However, the pvm_psend()-pvm_precv()
bandwidth is almost as efficient. In fact, pvm_psend()
is built on top of isend,
a configuration that explains its good performance (see ![]() ).
In Figure
).
In Figure ![]() , we see that there can be an
extra buffering if the message arrives before the receive is posted.
The system buffers any incoming message for which no receive has been
posted.
In a ``ping-pong"
test, however, the receive is always posted, and this extra buffering never occurs.
, we see that there can be an
extra buffering if the message arrives before the receive is posted.
The system buffers any incoming message for which no receive has been
posted.
In a ``ping-pong"
test, however, the receive is always posted, and this extra buffering never occurs.
As on the CM-5, pvm_send()-pvm_recv()
with PvmDataInPlace is much less efficient.
First, unlike pvm_psend()-pvm_precv(), it involves an actual data-unpacking on the receiving end,
as shown in Figure ![]() . Second,
There may be an extra buffering on the receiving end.
We should, however,
realize better relative performance than on the CM-5 because csend()
does not do a systematic
extra data copy, as was the case on the CM-5 with CMMD_send_noblock(). However,
there could be an extra data copy as a result of the
PvmDataInPlace protocol.
When the receiver receives the header, it begins to build a PVM buffer,
as explained in section
. Second,
There may be an extra buffering on the receiving end.
We should, however,
realize better relative performance than on the CM-5 because csend()
does not do a systematic
extra data copy, as was the case on the CM-5 with CMMD_send_noblock(). However,
there could be an extra data copy as a result of the
PvmDataInPlace protocol.
When the receiver receives the header, it begins to build a PVM buffer,
as explained in section ![]() . Meanwhile, the data may arrive before the receive
is posted.
In that case, the system does an extra buffering on the receiving end.
This is the reason that
the relative performance of PvmDataInPlace compared with that
of pvm_psend()-pvm_precv() is roughly the same as it is on the CM-5.
This also explains the sudden jump when the message size crosses over
. Meanwhile, the data may arrive before the receive
is posted.
In that case, the system does an extra buffering on the receiving end.
This is the reason that
the relative performance of PvmDataInPlace compared with that
of pvm_psend()-pvm_precv() is roughly the same as it is on the CM-5.
This also explains the sudden jump when the message size crosses over
 Bytes (1 MB). The default size of the Paragon system buffer is 1 MB,
and
Bytes (1 MB). The default size of the Paragon system buffer is 1 MB,
and  of that is used to buffer incoming messages. The 1-MB message
could not fit in the buffer, so it was held up briefly and then copied
into the PVM buffer directly. That, ironically, resulted in better
performance.
of that is used to buffer incoming messages. The 1-MB message
could not fit in the buffer, so it was held up briefly and then copied
into the PVM buffer directly. That, ironically, resulted in better
performance.
Of course, pvm_send()-pvm_recv() with PvmDataRaw is even less efficient, because it also involves data packing and unpacking. In addition, the message must be buffered by the system, because pvm_recv polls to check the message length before accepting it.
The little blip in the middle of the pvm_send()-pvm_recv() curve corresponds to the system page size.