Figure ![]() (a) shows the transfer time between two nodes for
small messages (up to 1024 bytes).
(a) shows the transfer time between two nodes for
small messages (up to 1024 bytes).
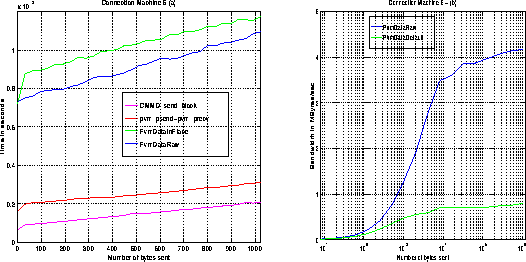
Figure: (a) Latency on the CM-5 : PVM3 - CMMD - (b) Bandwidth : PvmDataDefault
We computed the latencies from Figure ![]() using a least squares interpolation.
They are given in the following table.
using a least squares interpolation.
They are given in the following table.
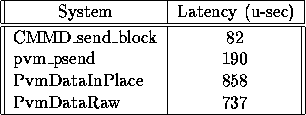
We observe that the latency for CMMD_send_block()-CMMD_receive_block() is the lowest. The latency for pvm_psend()-pvm_precv() is higher, since these routines are built on top of the CMMD routines. Moreover, pvm_psend() is much more complex than CMMD_send_block(), since it uses CMMD_send_async() and accepts incoming messages while waiting for its sending operation to be completed, putting them into a queue (the semantics of pvm_psend() implies that no deadlock should occur and that the buffer is ready for reuse when it returns).
The latency of pvm_send()-pvm_recv() is of course much higher than that of
pvm_psend()-pvm_precv(). This is because of the data packing-unpacking and the use
of CMMD_send_noblock(). We notice that the latency
is higher with PvmDataInPlace
than with PvmDataRaw, which can be seen from Figure ![]() .
With PvmDataInPlace,
pvm_send() has much more ``work" to do than with PvmDataRaw.
Before sending the first data to the receiver, a header must be sent, to inform the receiver
about the size of the messages to be expected. This header is built in the PVM space
and must be sent separately because it is not contiguous with the data.
In the figure, the sending of the
header corresponds to the blue arrow number 1. Once it has received the
header, the receiver builds a PVM buffer according to the information contained
in the header, symbolized by the dashed black arrow on the figure. Then it begins
accepting the data in this buffer (blue arrows 2). This process is repeated
with the next header if there is one.
In our small program, we have only one header of data to transmit. Thus, pvm_send() will
send a header and then the data. The extra cost of the header is the penalty for
short messages.
.
With PvmDataInPlace,
pvm_send() has much more ``work" to do than with PvmDataRaw.
Before sending the first data to the receiver, a header must be sent, to inform the receiver
about the size of the messages to be expected. This header is built in the PVM space
and must be sent separately because it is not contiguous with the data.
In the figure, the sending of the
header corresponds to the blue arrow number 1. Once it has received the
header, the receiver builds a PVM buffer according to the information contained
in the header, symbolized by the dashed black arrow on the figure. Then it begins
accepting the data in this buffer (blue arrows 2). This process is repeated
with the next header if there is one.
In our small program, we have only one header of data to transmit. Thus, pvm_send() will
send a header and then the data. The extra cost of the header is the penalty for
short messages.
Note that if we use PvmDataInPlace to send  noncontiguous
different data, pvm_send() actually sends
noncontiguous
different data, pvm_send() actually sends 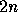 messages. Hence, it is highly
inefficient to use PvmDataInPlace instead of PvmDataRaw to send a large
amount of noncontiguous small data.
messages. Hence, it is highly
inefficient to use PvmDataInPlace instead of PvmDataRaw to send a large
amount of noncontiguous small data.