Figure ![]() shows the way the pvm_psend()-pvm_precv(), PvmDataInPlace,
and PvmDataRaw are implemented on the MPPs.
In the rest of this paper, we will frequently refer to
this figure in order to discuss its impact on the performance of PVM.
Note that in the figure, we have presented the steps of pvm_send() and
pvm_recv() for two noncontiguous data in the user space.
We have also represented
the possible extra buffering in the native system
on the receiving end.
This is the way buffering is done on the Intel Paragon. On the CM-5 and the SP2, however, the buffering
is done on the sending end for the native asynchronous blocking send.
shows the way the pvm_psend()-pvm_precv(), PvmDataInPlace,
and PvmDataRaw are implemented on the MPPs.
In the rest of this paper, we will frequently refer to
this figure in order to discuss its impact on the performance of PVM.
Note that in the figure, we have presented the steps of pvm_send() and
pvm_recv() for two noncontiguous data in the user space.
We have also represented
the possible extra buffering in the native system
on the receiving end.
This is the way buffering is done on the Intel Paragon. On the CM-5 and the SP2, however, the buffering
is done on the sending end for the native asynchronous blocking send.
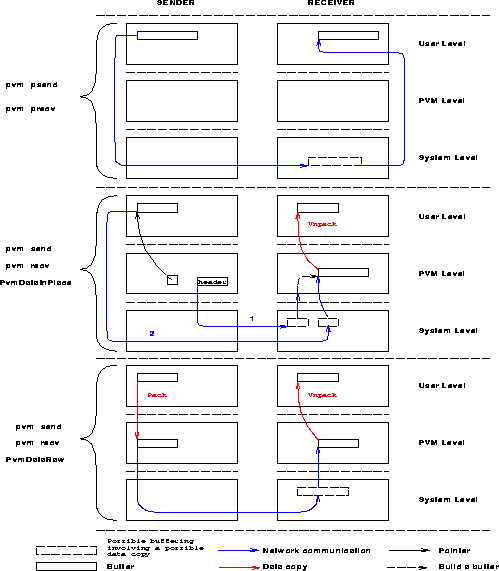
Figure: PVM implementation on MPPs