




Given the results of the communication analysis in a program segment, the performance estimator can be used to predict the performance of that program segment on the target machine. The realization of such an estimator requires a simple static model of performance that is based on (1) target machine parameters such as the number of processors, the message startup and transmission costs, and the average times to perform different floating-point operations; (2) the size of the input data set; and (3) the data partitioning scheme.
We undertook a study of published performance models [Chen:88b], [Fox:88a], [Gustafson:88a], [Saltz:87b] for use in the performance estimator, and noticed that these theoretical models did not give accurate predictions in many cases. We concluded that the theoretical models suffered from the following deficiencies:\
Our effort to correct these defects resulted in an increased complexity of the model, and also necessitated the introduction of several machine-specific features. We felt that this was undesirable, and decided to investigate alternative methods [Balasundaram:90d].
We constructed a program that tested a series of communication patterns using a set of basic low-level portable communication utilities. This program, called a ``training set,'' is executed once on the target machine. The program computes timings for the different communication operations and averages them over all the processors. These timings are determined for a sequence of increasing data sizes. Since the graph of communication cost versus data size is usually a linear function, it can easily be described by specifying a few parameters (e.g., the slope). The training set thus generates a table whose entries contain the minimal information necessary to completely define the performance characteristic for each communication utility. This table is used in place of the theoretical model for the purposes of performance prediction.
Figure 13.10 shows some communication cost characteristics created using a part of our training set on 32 processors of an nCUBE. The data space was assumed to be a two-dimensional array that was partitioned columnwise; that is, each processor was assigned a set of consecutive columns. The communication utilities tested here are:\
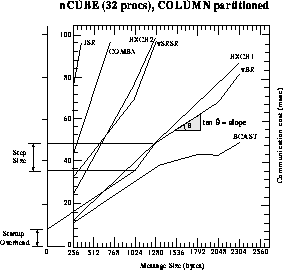
Figure 13.10: Communication cost characteristics of some EXPRESS utilities on the
nCUBE
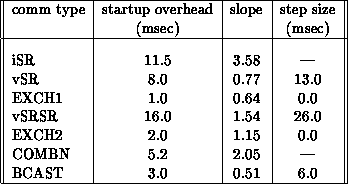
The table generated by the training set for the characteristics shown in Figure 13.10 is:\
The communication cost estimate for a particular data size is then calculated using the formula:\

where ``pkt size'' is the size of each message packet, which on the nCUBE
is 1024 bytes (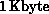 ).
).
The static performance model is meant primarily to help the programmer discriminate between different data partitioning schemes. Our approach is to provide the programmer with the necessary tools to experiment with several data partitioning strategies, until he can converge on the one that is likely to give him a satisfactory performance. The tool provides feedback information about performance estimates each time a partitioning is done by the programmer.