




Factorization of Full Matrices
LU factorization of
dense matrices, and the closely related Gaussian
elimination algorithm, are widely used in
the solution of linear systems of equations of the form 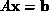 . LU factorization expresses the coefficient matrix, A, as the
product of a lower triangular matrix, L, and an upper triangular
matrix, U. After factorization, the original system of equations can
be written as a pair of triangular systems,
. LU factorization expresses the coefficient matrix, A, as the
product of a lower triangular matrix, L, and an upper triangular
matrix, U. After factorization, the original system of equations can
be written as a pair of triangular systems,
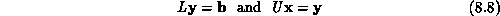
The first of the systems can be solved by forward reduction, and then back substitution can be used to solve the second
system to give x. If A is an 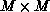 matrix, LU
factorization proceeds in M-1 steps, in the kof which column
k of L and row k of U are found,
matrix, LU
factorization proceeds in M-1 steps, in the kof which column
k of L and row k of U are found,

and the entries of A in a ``window'' extending from column k+1 to M-1 and row k+1 to M-1 are updated,
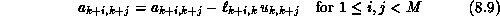
Partial pivoting is usually performed to improve numerical stability. This involves reordering the rows or columns of A.
In the absence of pivoting, the row- and column-oriented decompositions involve almost the same amounts of communication and computation. However, the row-oriented approach is generally preferred as it is more convenient for the back substitution phase [Chu:87a], [Geist:86a], although column-based algorithms have been proposed [Li:87a], [Moler:86a]. A block-oriented decomposition minimizes the amount of data communicated, and is the best approach on hypercubes with low message latency. However, since the block decomposition generally involves sending shorter messages, it is not suitable for machines with high message latency. In all cases, pipelining is the most efficient way of broadcasting rows and columns of the matrix since it minimizes the idle time that a processor must wait when participating in a broadcast , and effectively overlaps communication and calculation.
Load balance is an important issue in LU factorization. If a linear decomposition is used, the computation will be imbalanced and processors will become idle once they no longer contain matrix entries in the computational window. A scattered decomposition is much more effective in keeping all the processors busy, as shown in Figure 8.5. The load imbalance is least when a scattered block-oriented decomposition is used.
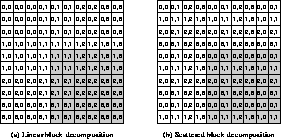
Figure 8.5: The Shaded Area in These Two Figures Shows the Computational Window
at the Start of Step Three of the LU Factorization Algorithm. In (a) we see
that by this stage the processors in the first row and column of the processor
grid have become idle if a linear block decomposition is used. In contrast,
in (b) we see that all processors continue to be involved in the computation
if a scattered block decomposition is used.
At Caltech, Van de Velde has investigated LU factorization of full matrices for a number of different pivoting strategies, and for various types of matrix decomposition on the Intel iPSC/2 hypercube and the Symult 2010 [Velde:90a]. One observation based on this work was that if a linear decomposition is used, then in many cases pivoting results in a faster algorithm than with no pivoting, since the exchange of rows effectively randomizes the decomposition, resulting in better load balance. Van de Velde also introduces a clever enhancement to the standard concurrent partial pivoting procedure. To illustrate this, consider partial pivoting over rows. Usually, only the processors in a single-processor column are involved in the search for the pivot candidate, and the other processors are idle at this time. In Van de Velde's multirow pivoting scheme, in each processor column a search for a pivot is conducted concurrently within a randomly selected column of the matrix. This incurs no extra cost compared with the standard pivoting procedure, but improves the numerical stability. A similar multicolumn pivoting scheme can be used when pivoting over columns. Van de Velde concludes from his extensive experimentation with LU factorization schemes that a scattered decomposition generally results in a more efficient algorithm on the iPSC/2 and Symult 2010, and his work illustrates the importance of decomposition and pivoting strategy in determining load balance, and hence concurrent efficiency.
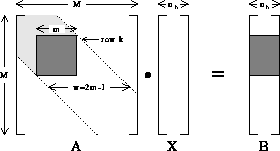
Figure 8.6: Schematic Representation of Step k of LU Factorization for
an 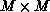 Matrix, A, with Bandwidth w. The
Matrix, A, with Bandwidth w. The
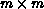 computational window is shown as a dark-shaded square, and
matrix entries in this region are updated at step k. The
light-shaded part of the band above and to the left of the window has
already been factorized, and in an in-place algorithm contains the
appropriate columns and rows of L and U. The unshaded part of the
band below and to the right of the window has not yet been modified.
The shaded region of the matrix B represents the
computational window is shown as a dark-shaded square, and
matrix entries in this region are updated at step k. The
light-shaded part of the band above and to the left of the window has
already been factorized, and in an in-place algorithm contains the
appropriate columns and rows of L and U. The unshaded part of the
band below and to the right of the window has not yet been modified.
The shaded region of the matrix B represents the 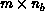 window
updated in step k of forward reduction, and in
step M-k-1 of back substitution.
window
updated in step k of forward reduction, and in
step M-k-1 of back substitution.
LU Factorization of Banded Matrices
Aldcroft, et al. [Aldcroft:88a] have investigated the
solution of linear systems of equations by LU factorization, followed
by forward elimination and back substitution, when the coefficient
matrix, A, is an 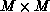 matrix of bandwidth
w=2m-1. The case of multiple right-hand sides was considered, so the
system may be written as AX=B, where X and B are
matrix of bandwidth
w=2m-1. The case of multiple right-hand sides was considered, so the
system may be written as AX=B, where X and B are 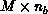 matrices. The LU factorization algorithm for banded matrices is
essentially the same as that for full matrices, except that the
computational window containing the entries of A updated in each step
is different. If no pivoting is performed, the window is of size
matrices. The LU factorization algorithm for banded matrices is
essentially the same as that for full matrices, except that the
computational window containing the entries of A updated in each step
is different. If no pivoting is performed, the window is of size
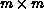 and lies along the diagonal, as shown in
Figure 8.6. If partial pivoting over rows is performed,
then fill-in will occur, and the window may attain a maximum size of
and lies along the diagonal, as shown in
Figure 8.6. If partial pivoting over rows is performed,
then fill-in will occur, and the window may attain a maximum size of
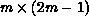 . In the work of Aldcroft, et al. the size of the
window was allowed to vary dynamically. This involved some additional
bookkeeping, but is more efficient than working with a fixed window of
the maximum size. Additional complications arise from only storing the
entries of A within the band in order to reduce memory usage.
. In the work of Aldcroft, et al. the size of the
window was allowed to vary dynamically. This involved some additional
bookkeeping, but is more efficient than working with a fixed window of
the maximum size. Additional complications arise from only storing the
entries of A within the band in order to reduce memory usage.
As in the full matrix case, good load balance is ensured by using a scattered block decomposition for the matrices. As noted previously, this choice of decomposition also minimizes communication cost on low latency multiprocessors, such as the Caltech/JPL Mark II hypercube used in this work, but may not be optimal for machines in which the message startup cost is substantial.
A comparison between an analytic performance model and results on the
Caltech/JPL Mark II hypercube shows that the concurrent overhead for the
LU factorization algorithm falls to zero as 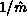 , where
, where
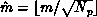 . This is true in both the pivoting
and non-pivoting cases. Thus, the LU factorization algorithm scales well to
larger machines.
. This is true in both the pivoting
and non-pivoting cases. Thus, the LU factorization algorithm scales well to
larger machines.