




Due to its irregular nature, string is an extremely good benchmark of
the scalar performance of a computer. Hence, we timed it on
several machines we had access to, yielding the numbers in
Table 7.1. Note that we timed one processor of
the parallel machines. We see immediately that the Sun 4/60, known as
the SPARCstation 1, had the highest performance of the Suns we tested.
Moreover, this machine (running with TI 8847 floating-point processor
at clock rate of 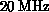 ) is as fast as the Motorola 88000
processor (at
) is as fast as the Motorola 88000
processor (at 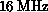 ) which is used in the TC2000 Butterfly.
Turning to the hypercubes, we see that the nCUBE-2 is faster than the
Meiko, which is twice as fast as the (scalar) Symult, which in turn is
twice as fast as the nCUBE-1, per processor, for the string program.
We have also run on the Weitek vector processors of the Mark III and
Symult. The vector processors are faster than the scalar processors,
but since string is entirely scalar, it does not run very efficiently
on the vector processors and, hence, is still slower than on the
Sun 4/60. The Mark III is as fast as the Symult, despite having
one-third the clock rate, because it has a high-performance cache
between its vector processor and memory. We have also timed the code
on the new IBM and Hewlett-Packard workstations, and Cimarron Boozer of
Sky Computers has optimized the code for the Intel i860. As a final
comparison, the modern RISC workstations run the string code as fast as
the CRAY X-MP.
) which is used in the TC2000 Butterfly.
Turning to the hypercubes, we see that the nCUBE-2 is faster than the
Meiko, which is twice as fast as the (scalar) Symult, which in turn is
twice as fast as the nCUBE-1, per processor, for the string program.
We have also run on the Weitek vector processors of the Mark III and
Symult. The vector processors are faster than the scalar processors,
but since string is entirely scalar, it does not run very efficiently
on the vector processors and, hence, is still slower than on the
Sun 4/60. The Mark III is as fast as the Symult, despite having
one-third the clock rate, because it has a high-performance cache
between its vector processor and memory. We have also timed the code
on the new IBM and Hewlett-Packard workstations, and Cimarron Boozer of
Sky Computers has optimized the code for the Intel i860. As a final
comparison, the modern RISC workstations run the string code as fast as
the CRAY X-MP.
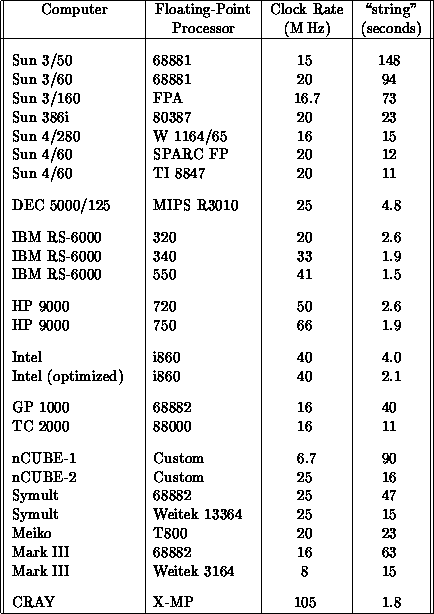
Table 7.1: Time Taken to Execute the String Program
We should emphasize that these performances are for scalar
codes. A completely different picture emerges for codes which
vectorize well, like QCD. QCD, with dynamical fermions, runs on the
CRAY X-MP at around 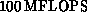 and pure-gauge QCD runs on one
processor of the Mark III at
and pure-gauge QCD runs on one
processor of the Mark III at 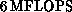 . In contrast, the
Sun 4/60 only achieves about
. In contrast, the
Sun 4/60 only achieves about 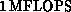 for pure-gauge QCD.
This ratio of QCD performance (which we may claim as the ``realistic
peak'' performance of the machines) 100:6:1 compares with 5:0.7:1 for
strings. Thus, these two calculations from one area of physics
illustrate clearly that the preferred computer architecture depends on
the problem.
for pure-gauge QCD.
This ratio of QCD performance (which we may claim as the ``realistic
peak'' performance of the machines) 100:6:1 compares with 5:0.7:1 for
strings. Thus, these two calculations from one area of physics
illustrate clearly that the preferred computer architecture depends on
the problem.