The LINPACK benchmark features solving a system of linear
equation, 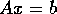 . The benchmark results
examined here are for two distinct benchmark problems.
The first problem uses Fortran software from the LINPACK
software package to solve a matrix problem of
order 100. That is, the matrix
. The benchmark results
examined here are for two distinct benchmark problems.
The first problem uses Fortran software from the LINPACK
software package to solve a matrix problem of
order 100. That is, the matrix 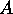 has 100 rows and columns
and is said to be of size
has 100 rows and columns
and is said to be of size 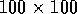 .
The software used in this experiment is based on
two routines from the LINPACK collection:
DGEFA and DGESL.
DGEFA performs the decomposition with partial pivoting, and
DGESL uses that decomposition to solve the given system
of linear equations.
Most of the time -
.
The software used in this experiment is based on
two routines from the LINPACK collection:
DGEFA and DGESL.
DGEFA performs the decomposition with partial pivoting, and
DGESL uses that decomposition to solve the given system
of linear equations.
Most of the time - 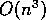 floating-point operations -
is spent in DGEFA. Once the matrix has been decomposed,
DGESL is used to find the solution;
this requires
floating-point operations -
is spent in DGEFA. Once the matrix has been decomposed,
DGESL is used to find the solution;
this requires 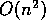 floating-point operations.
floating-point operations.
DGEFA and DGESL in turn call three BLAS routines: DAXPY, IDAMAX, and
DSCAL. For the size 100 benchmark, the BLAS used are
written in Fortran.
By far the major portion of time - over 90% at order 100 -
is spent in subroutine DAXPY.
DAXPY is used to multiply a scalar, 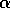 ,
times a vector,
,
times a vector,  , and add the results to another vector,
, and add the results to another vector,  .
It is called approximately
.
It is called approximately 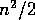 times by DGEFA
and
times by DGEFA
and 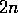 times by DGESL with vectors of varying length.
The statement
times by DGESL with vectors of varying length.
The statement 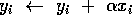 ,
which forms an element of the DAXPY operation,
is executed approximately
,
which forms an element of the DAXPY operation,
is executed approximately 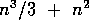 times, which gives rise to roughly
times, which gives rise to roughly 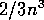 floating-point operations in the solution.
Thus, the benchmark requires roughly 2/3 million floating-point operations.
floating-point operations in the solution.
Thus, the benchmark requires roughly 2/3 million floating-point operations.
The statement 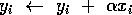 ,
besides the floating-point addition and floating-point
multiplication, involves a few one-dimensional index operations
and storage references.
While the LINPACK routines DGEFA and DGESL involve two-dimensional
arrays references, the BLAS refer to one-dimensional
arrays. The LINPACK routines in general have been organized to
access two-dimensional arrays by column. In DGEFA, the call
to DAXPY passes an address into the two-dimensional array A,
which is then treated as a one-dimensional reference within DAXPY.
Since the indexing is
down
a column of the two-dimensional array,
the references to the one-dimensional array are sequential
with unit stride. This is a performance enhancement over, say,
addressing across the column of a two-dimensional array.
Since Fortran dictates that two-dimensional arrays be stored by column
in memory, accesses to consecutive elements of a column lead
to simple index calculations. References to
consecutive elements differ by one word instead of
by the leading dimension of the two-dimensional array.
,
besides the floating-point addition and floating-point
multiplication, involves a few one-dimensional index operations
and storage references.
While the LINPACK routines DGEFA and DGESL involve two-dimensional
arrays references, the BLAS refer to one-dimensional
arrays. The LINPACK routines in general have been organized to
access two-dimensional arrays by column. In DGEFA, the call
to DAXPY passes an address into the two-dimensional array A,
which is then treated as a one-dimensional reference within DAXPY.
Since the indexing is
down
a column of the two-dimensional array,
the references to the one-dimensional array are sequential
with unit stride. This is a performance enhancement over, say,
addressing across the column of a two-dimensional array.
Since Fortran dictates that two-dimensional arrays be stored by column
in memory, accesses to consecutive elements of a column lead
to simple index calculations. References to
consecutive elements differ by one word instead of
by the leading dimension of the two-dimensional array.
If we examine the algorithm used in LINPACK and look at how the data
are referenced, we see that at each step of the factorization process
there are operations that
modify a full submatrix of data. This update causes a block of data
to be read, updated, and written back to central memory. The number of
floating-point operations is , and the number of
data references, both loads and stores, is .
Thus, for every
add/multiply
pair we must perform a load and store of the elements,
unfortunately obtaining no reuse of data.
Even though the operations are fully vectorized, there is a significant
bottleneck in data movement, resulting in poor performance.
To achieve high-performance rates, this
operation-to-memory-reference rate
must be higher.
The bottleneck is in moving data and the rate of execution are limited by these quantities. We can see this by examining the rate of data transfers and the peak performance.