Machines of this type are sometimes also known as processor-array
/ machines [#hockney#
All currently available DM-SIMD machines use a front-end
processor to which they are connected by a datapath. I/O may be through the
front-end system, by the processor array machine itself or both.
Figure 2 might suggest that all processors in such systems are connected in a
2-D grid and indeed, the interconnection topology of this type of machines
always includes the 2-D grid. As opposing ends of each grid line are also
always connected the topology is rather that of a torus. For several machines
this is not the only interconnection scheme: They might also be connected in
3-D, diagonally, or more complex structures.
It is possible to exclude processors in the array from executing an instruction
on certain logical conditions, but this means that for the time of this
instruction these processors are idle (a direct consequence of the SIMD type
operation) which immediately lowers the performance. Another factor that may
adversely affect the speed occurs when data required by processor i resides
in the memory of processor j (in fact, as this occurs for all processors at
the same time this effectively means that data will have to be permuted across
the processors). To access the data in processor j, the data will have to be
fetched by this processor and then send through the routing network to
processor i. This may be fairly time consuming. For both reasons mentioned
DM-SIMD machines are rather specialised in their use when one wants to employ
their full parallelism. Generally, they perform excellently on digital signal
and image processing and on certain types of Monte Carlo simulations where
virtually no data exchange between processors is required and exactly the same
type of operations is done on massive datasets with a size that can be made to
fit comfortable in these machines.
The control processor as depicted in Figure 2 may be more or less
intelligent. It issues the instruction sequence that will be executed
by the processor array. In the worst case (that means a less autonomous
control processor) when an instruction is not fit for execution on the
processor array (e.g., a simple print instruction) it might be
offloaded to the front-end processor which may be much slower than
execution on the control processor. In case of a more autonomous
control processor this can be avoided thus saving processing interrupts
both on the front-end and the control processor. Most DM-SIMD systems
have the possibility to handle I/O independently from the front/end
processors. This is not only favourable because the communication
between the front-end and back-end systems is avoided. The
(specialised) I/O devices for the processor-array system is generally
much more efficient in providing the necessary data directly to the
memory of the processor array. Especially for very data-intensive
applications like radar- and image processing such I/O systems are very
important.
A feature that is peculiar to this type of machines is that the
processors sometimes are of a very simple bit-serial type, i.e., the
processors operate on the data items bitwise, irrespective of their
type. So, e.g., floating-point operations have either to be implemented in
software, or to be dealt with by floating-point coprocessors. As the number of
processors in this type of systems is mostly large (1024 or larger, the
Alenia Quadrics is a notable exception, however), the natural slowness
of the processors can be often offset by their number, while the cost
per processor is quite low as compared to full floating-point processors. When floating-point
coprocessors are added their number is usually much lower because of
the cost argument. An advantage of bit-serial processors is that they
may operate on operands of any length. Both for random number
generation (which often boils down to logical manipulation of bits) and
for signal processing this is fortunate because in both cases operands
of only 1-8 bits are abundant. As the execution time for bit-serial
machines is proportional to the length of the operands, this may result
insignificant speedups.
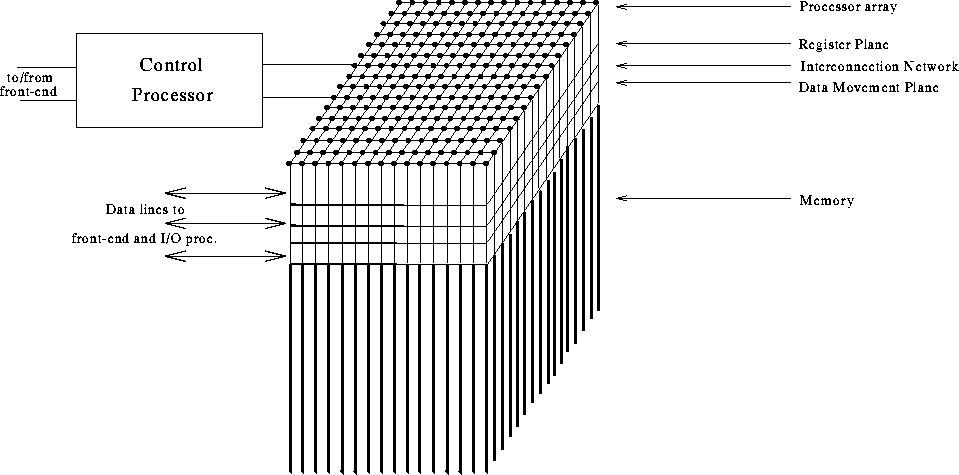
Figure 2: A generic block diagram of a distributed memory SIMD
machine.
![]()
![]()
![]()
![]()
Next: Shared-memory MIMD machines
Up: The Main Architectural Classes
Previous: Shared-memory SIMD machines
Jack Dongarra
Sat Feb 10 15:12:38 EST 1996