buffering A message passing program is dependent on the buffering of messages if its communication graph has a cycle. The communication graph is a directed graph in which the nodes represent MPI communication calls and the edges represent dependencies between these calls: a directed edge uv indicates that operation v might not be able to complete before operation u is started. Calls may be dependent because they have to be executed in succession by the same process, or because they are matching send and receive calls.

The execution of the code results in the
dependency graph illustrated in Figure ![]() ,
for the case of a three
process group.
,
for the case of a three
process group.
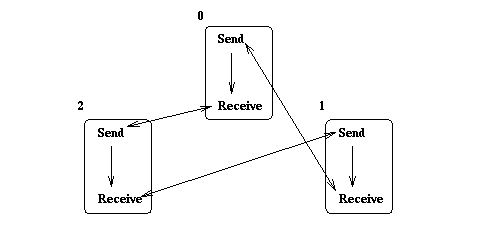
Figure: Cycle in communication graph for cyclic shift.
The arrow from each send to the following receive executed by the same process reflects the program dependency within each process: the receive call cannot be executed until the previous send call has completed. The double arrow between each send and the matching receive reflects their mutual dependency: Obviously, the receive cannot complete unless the matching send was invoked. Conversely, since a standard mode send is used, it may be the case that the send blocks until a matching receive occurs.
The dependency graph has a cycle. This code will only work if the system provides sufficient buffering, in which case the send operation will complete locally, the call to MPI_Send() will return, and the matching call to MPI_Recv() will be performed. In the absence of sufficient buffering MPI does not specify an outcome, but for most implementations deadlock will occur, i.e., the call to MPI_Send() will never return: each process will wait for the next process on the ring to execute a matching receive. Thus, the behavior of this code will differ from system to system, or on the same system, when message size (count) is changed.
There are a number of ways in which a shift operation can be performed portably using MPI. These are
If at least one process in a shift operation calls the receive routine before the send routine, and at least one process calls the send routine before the receive routine, then at least one communication can proceed, and, eventually, the shift will complete successfully. One of the most efficient ways of doing this is to alternate the send and receive calls so that all processes with even rank send first and then receive, and all processes with odd rank receive first and then send. Thus, the following code is portable provided there is more than one process, i.e., clock and anticlock are different:
if (rank%2) {
MPI_Recv (buf2, count, MPI_INT, anticlock, tag, comm, &status);
MPI_Send (buf1, count, MPI_INT, clock, tag, comm);
}
else {
MPI_Send (buf1, count, MPI_INT, clock, tag, comm);
MPI_Recv (buf2, count, MPI_INT, anticlock, tag, comm, &status);
}
The resulting communication graph is illustrated in
Figure 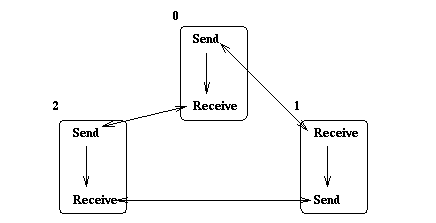
Figure: Cycle in communication graph is broken by reordering
send and receive.
If there is only one process then clearly blocking send and receive routines cannot be used since the send must be called before the receive, and so cannot complete in the absence of buffering.
We now consider methods for performing shift operations that work even if there is only one process involved. A blocking send in buffered mode can be used to perform a shift operation. In this case the application program passes a buffer to the MPI communication system, and MPI can use this to buffer messages. If the buffer provided is large enough, then the shift will complete successfully. The following code shows how to use buffered mode to create a portable shift operation.
... MPI_Pack_size (count, MPI_INT, comm, &buffsize) buffsize += MPI_BSEND_OVERHEAD userbuf = malloc (buffsize) MPI_Buffer_attach (userbuf, buffsize); MPI_Bsend (buf1, count, MPI_INT, clock, tag, comm); MPI_Recv (buf2, count, MPI_INT, anticlock, tag, comm, &status);
MPI guarantees that the buffer supplied by a call to
MPI_Buffer_attach()
will be used if it is needed to buffer the message.
(In an implementation
of MPI that provides sufficient buffering,
the user-supplied buffer may be
ignored.)
Each buffered send operations can complete locally, so
that a deadlock will not occur. The acyclic communication graph for
this modified code is shown in Figure ![]() .
Each receive depends on the matching send, but the
send does not depend anymore on the matching receive.
.
Each receive depends on the matching send, but the
send does not depend anymore on the matching receive.
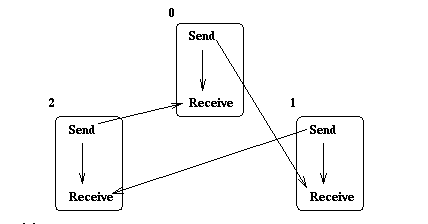
Figure: Cycle in communication graph is broken by using
buffered sends.
Another approach is to use nonblocking communication. One can either use a nonblocking send, a nonblocking receive, or both. If a nonblocking send is used, the call to MPI_Isend() initiates the send operation and then returns. The call to MPI_Recv() can then be made, and the communication completes successfully. After the call to MPI_Isend(), the data in buf1 must not be changed until one is certain that the data have been sent or copied by the system. MPI provides the routines MPI_Wait() and MPI_Test() to check on this. Thus, the following code is portable,
... MPI_Isend (buf1, count, MPI_INT, clock, tag, comm, &request); MPI_Recv (buf2, count, MPI_INT, anticlock, tag, comm, &status); MPI_Wait (&request, &status);
The corresponding acyclic communication graph is shown in
Figure ![]() .
.
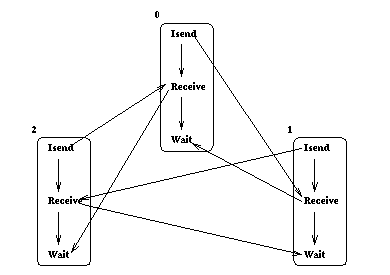
Figure: Cycle in communication graph is broken by using
nonblocking sends.
Each receive operation depends on the matching send, and each wait depends on the matching communication; the send does not depend on the matching receive, as a nonblocking send call will return even if no matching receive is posted.
(Posted nonblocking communications do consume resources: MPI has to keep track of such posted communications. But the amount of resources consumed is proportional to the number of posted communications, not to the total size of the pending messages. Good MPI implementations will support a large number of pending nonblocking communications, so that this will not cause portability problems.)
An alternative approach is to perform a nonblocking receive first to initiate (or ``post'') the receive, and then to perform a blocking send in standard mode.
... MPI_Irecv (buf2, count, MPI_INT, anticlock, tag, comm, &request); MPI_Send (buf1, count, MPI_INT, clock, tag, comm): MPI_Wait (&request, &status);
The call to MPI_Irecv() indicates to MPI that incoming data should be stored in buf2; thus, no buffering is required. The call to MPI_Wait() is needed to block until the data has actually been received into buf2. This alternative code will often result in improved performance, since sends complete faster in many implementations when the matching receive is already posted.
Finally, a portable shift operation can be implemented using the routine MPI_Sendrecv(), which was explicitly designed to send to one process while receiving from another in a safe and portable way. In this case only a single call is required;
...
MPI_Sendrecv (buf1, count, MPI_INT, clock, tag,
buf2, count, MPI_INT, anticlock, tag, comm, &status);