We measured latency and bandwidth on a number of different multiprocessors.
Each architecture is briefly summarized in Appendix A.
Table 1 shows the measured latency, bandwidth,
and ![]() for nearest neighbor communication.
The table also includes the peak bandwidth as stated by the vendor.
For comparison, typical data rates and latencies are reported for
several local area network technologies.
for nearest neighbor communication.
The table also includes the peak bandwidth as stated by the vendor.
For comparison, typical data rates and latencies are reported for
several local area network technologies.
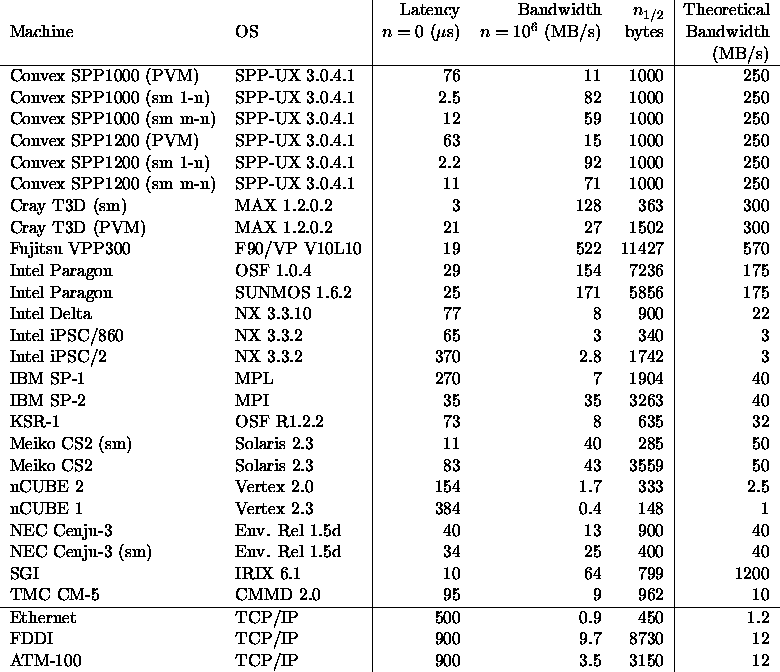
Table 1: Multiprocessor Latency and Bandwidth.
Figure 2 details the message-passing times of various multiprocessors over a range of message sizes. For small messages, the fixed overhead and latency dominate transfer time. For large message, the transfer time rises linearly with message size. Figure 3 illustrates the asymptotic behavior of bandwidth for large message sizes. It is possible to reduce latency on the shared-memory architectures by using shared-memory copy operations. These operations usually involve only one-processor and assume that the message is ready to be retrieved on the other processor. Figure 4 compares the message transfer times for shared-memory get's and explicit message passing for the Cray T3D, Meiko, and NEC. Current research in ``active messages'' is seeking ways to reduce message-passing overhead by eliminating context switches and message copying. Finally, Figure 5 graphically summarizes the communication performance of the various multiprocessors in a two-dimensional message-passing metric space. The upper-left region is the high performance area, lower performance and LAN networks occupy the lower performance region in the lower right.
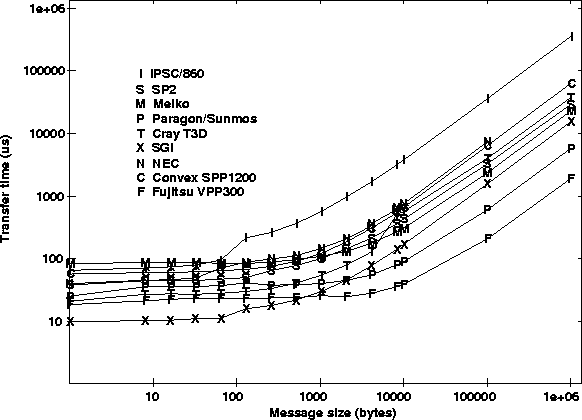
Figure 2: Message-passing transfer time in microseconds for various multiprocessors and messages sizes.
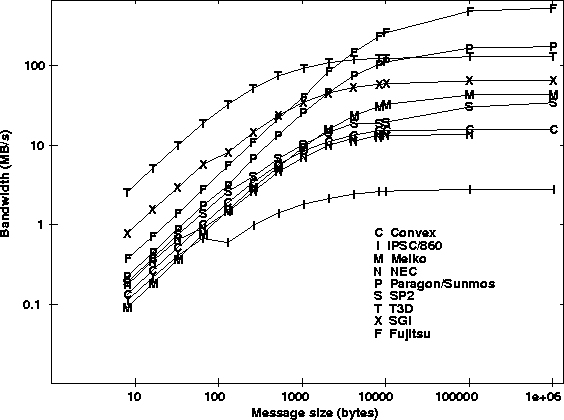
Figure 3: Bandwidth in megabytes/second for various multiprocessors and messages sizes.
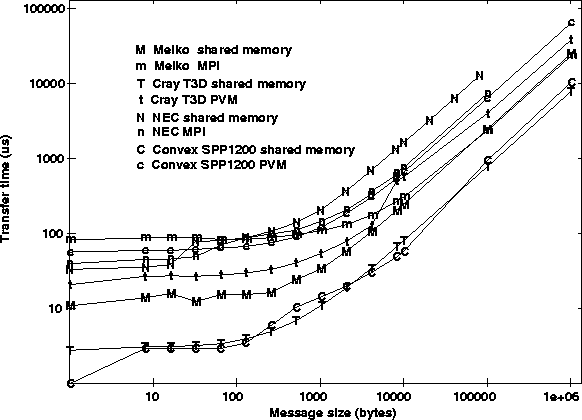
Figure 4: Transfer time in microseconds for both shared-memory operations
and explicit message passing.
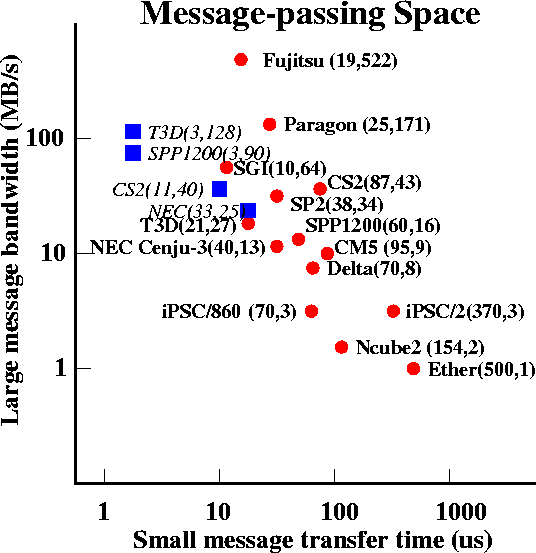
Figure 5: Latency/bandwidth space for 0-byte message (latency) and
1 MB message (bandwidth). Block points represent shared-memory copy
performance.
Since clusters of workstations on a network are often used as a
virtual parallel machine, it is interesting to compare latency and
bandwidths for various local area networks.
Most communications over local area networks is done with the
TCP/IP protocols, though proprietary API's may exist.
We measured latency for small messages using a UDP echo test.
TCP bandwidth was measured at the receiver with the ttcp
program using 50,000 byte messages and 50,000 byte window sizes.
Some newer operating systems support even larger window sizes,
which could provide higher bandwidths.
Most high-end workstations can transmit network data at or near
media data rates (e.g., 12 MB/second for FDDI).
Data rates of 73 MB/second for UDP have been reported between
Crays on HiPPI (and even over a wide-area using seven OC3's) [1].
Latency and bandwidth will depend as much on the efficiency of
the TCP/IP implementation as on the network interface hardware and media.
As with multiprocessors, the number of times the message is touched
is a critical parameter as is context-switch time.
Latencies for local area networks (Ethernet, FDDI, ATM, HiPPI) are
typically on the order of 500 ![]() s.
For wide-area networks, latency is usually dominated by distance
(speed of light) and is on the order of tens of milliseconds.
s.
For wide-area networks, latency is usually dominated by distance
(speed of light) and is on the order of tens of milliseconds.