We have outlined the basic parallel implementation of the three factorization routines. In this section, we provide performance results on the Intel iPSC/860, Touchstone Delta, and Paragon systems. We also discuss specific implementation details to improve performance and possible variations of the routines which might yield better performance.
The Intel iPSC/860 is a parallel architecture with up to 128 processing nodes. Each node consists of an i860 processor with 8 Mbytes of memory. The system is interconnected with a hypercube structure. The Delta system contains 512 i860-based computational nodes with 16 Mbytes /node, connected with a 2-D mesh communication network. The Intel Paragon located at the Oak Ridge National Laboratory has 512 computational nodes, interconnected with a 2-D mesh. Each node has 32 Mbytes of memory and two i860XP processors, one for computation and the other for communication. The Intel iPSC/860 and Delta machines both use the same 40MHz i860 processor, but the Delta has a higher communication bandwidth. Significantly higher performance can be attained on the Paragon system, since it uses the faster 50 MHz i860XP processor and has a larger communication bandwidth.
On each node all computation was performed in double precision arithmetic, using assembly-coded BLAS (Level 1, 2, and 3), provided by Intel. Communication was performed using the BLACS package, customized for the Intel systems. Most computation by the BLAS and communication by the BLACS are hidden within the PBLAS.
A good choice for the block size, 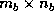 , was determined
experimentally
for each factorization on the given target machines.
For all performance graphs, results are presented for square matrices
with a square block size
, was determined
experimentally
for each factorization on the given target machines.
For all performance graphs, results are presented for square matrices
with a square block size 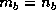 .
The numbers of floating point operations for an
.
The numbers of floating point operations for an 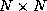 matrix
were assumed to be
matrix
were assumed to be 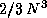 for the LU factorization,
for the LU factorization,
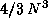 for the QR factorization,
and
for the QR factorization,
and 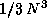 for the Cholesky factorization.
for the Cholesky factorization.