



Although Pentium processors are not applied in integrated parallel
systems these days, they play a major role in the cluster community as
most compute nodes in Beowulf clusters are of this type. Therefore we
briefly discuss also this type of processor. In fact, mostly the Xeon
processor is used as it can accommodate a larger cache than the
Pentium 4 and has some provisions for use in a multiprocessor
environment. As virtually all Intel-based clusters use 2-processor
nodes, the Xeon is the most appropriate processor. Apart from the
differences mentioned here the architecture of the Pentium 4 and the
Xeon are identical.
Intel only provides scant information on its processor. Therefore, a
rough block diagram of the P4 processor can only be synthesized from
various sources. It is shown in Figure 13.
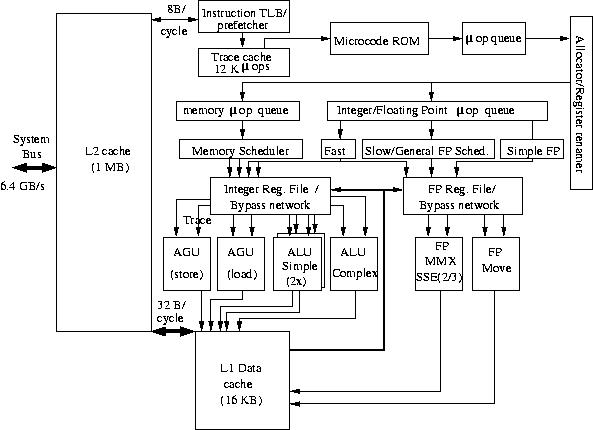
Figure 13: Block diagram of the Intel Xeon Nocona.
We show here the Xeon variant with the large secondary cache that with the
other additional features of the Nocona fits on chip because of the advanced 90
nm technology used to fabricate the chip. There are a number of distinctive
features with respect to the earlier Pentium generations. There are two main ways to increase the
performance of a processor: by raising the clock frequency and by
increasing the number of instructions per cycle (IPC). These two
approaches are generally in conflict: when one wants to increase the
IPC the chip will become more complicated. This will have a negative
impact on the clock frequency because more work has to be done and
organised within the same clock cycle. Very seldomly chip designers
succeed in raising both clock frequency and IPC simultaneously. Also in
the Pentium 4 this could not be done. Intel has chosen for a high clock
speed (initially about 40% more than that of the Pentium III with the
same fabrication technology) while the IPC decreased by 10--20%. This
still gives a net performance gain even if other changes would have
been made to the processor. To sustain the very high clock rate that
the present processors have, currently ≅ 3.8 GHz, a very deep instruction
pipeline is required. The instruction pipeline has no less than 31
stages, where the Pentium III had 10.
Although this favours a high clock rate, the penalty for a pipeline
miss (e.g., a branch mis-predict) is much heavier and therefore Intel
has improved the branch prediction by a increasing the size of the
Branch Target Buffer from 0.5 to 4 KB. In addition, the Pentium 4 has
an execution trace cache which holds partly decoded instructions of
former execution traces that can be drawn upon, thus foregoing the
instruction decode phase that might produce holes in the instruction
pipeline. The allocator dispatches the decoded instructions, "micro
operations", to the appropriate µop queue, one for memory
operations, another for integer and floating-point operations.
Two integer Arithmetic/Logical Units are kept simple in order to be
able to run them at twice the clock speed. In addition there is an ALU
for complex integer operations that cannot be executed within one
cycle. There is only one Floating-point functional unit that delivers
one result per cycle. However, besides the normal Floating-point Unit,
there also are additional units that execute the Streaming SIMD
Extensions 2 and 3 (SSE2/3) repertoire of instructions, a 144-member
instruction set, that is especially meant for multimedia, and 3-D
visualisation applications. The length of the operands for these units
is 128 bits. The Intel compilers have the ability to address the SSE2/3
units. This makes it in principle possible to achieve a two times
higher floating-point performance.
The Xeon Nocona boast so-called Hyperthreading: with the processor two threads
can run concurrently under some circumstances. This may for instance be used
for speculative execution of if branches. Experiments have shown that up
to 30% performance improvements can be attained for a variety of codes. In
practice the performance gain about 3--5%, however.
The primary cache was quite small by today's standards: 8 KB. This has been
doubled to 16 KB since the so-called Prescott implementation of the processor,
however, at the cost of a higher latency in shipping data to the functional
units. Where it was 2 cycles before, it has now increased to 3 cycles.
The largest difference with the former processors, however, is the ability to
run (and address) 64-bit codes, thereby following AMD, in fact copying the
approach used in the AMD Opteron and Athlon processors. The technique is called
Extended Memory 64 Technology (EM64T) by Intel. In principle it uses
``unused bits'' from in the instruction words of the x86 instruction set to
signal whether an 64-bit version of an instruction should be executed.
Of course some additional devices are needed for operating in 64-bit mode. These
include 8 new general purpose registers(GPRs), 8 new registers for SSE2/3
support, and 64-bit wide GPRs and instruction pointers.
It will depend heavily on the availability of compilers that are able to
take advantage of all the facilities present in the Nocona processor. (Intel
claims that a 30% performance improvement is possible).
If they can, the processor could be a interesting basis for HPC clusters.