




The communication analysis algorithm takes the internal data mappings, the dependence graph, and the loop nesting structure of the specified program segment as its input. For each processor the algorithm determines information about all communications the processor is involved in. We will now illustrate the communication analysis algorithm using the example program segments P1, P2, and P3, where P2 is derived from P1, and P3 from P2, respectively, by a transformation called loop distribution.
Substantial performance improvement can be achieved by performing various code transformations on the program segment. For example, the loop-distribution transformation [Wolfe:89a] often helps reduce the overhead of communication. Loop distribution splits a loop into a set of smaller loops, each containing a part of the body of the original loop. Sometimes, this allows communication to be done between the resulting loops, which may be more efficient than doing the communication within the original loop.
Consider the program segment P1. If A is partitioned by column and B by row, communication will be required within the inner loop to satisfy the value dependence of B on A. Each message communicates a single element of A. For small message sizes and a large number of messages, the fraction of communication time taken up by message startup overhead is usually quite large. Thus, program P1 will most likely give poor performance because it involves the communication of a large number of small messages.
However, if we loop-distributed the inner do i loop over the two
statements, the communication of A from the first do i loop to the
second do i loop can be done between the two new inner loops. This
allows each processor to finish computing its entire column partition of A in
the first do i loop, and then send its part of A to the appropriate
processors as larger messages, before starting computation of a partition of
B in the second do i loop. This communication is done only once for
each iteration of the outer do j loop, that is, a total of O(n)
communication steps. In comparison, program P1 requires communication within
the inner loop, which gives a total of O(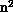 ) communication
steps:\
) communication
steps:\
*
do j = 2, n
do i = 2, n
A(i, j) =
enddo
do i = 2, n
B(i, j) =
enddo
enddo
MMMMMMMMMMMMMMMMMMMMMMMMMM¯P2. After loop distribution of i loop.
The reduction in the number of communication steps also results in greater
parallelism, since the two inner do i loops can be executed in parallel
by all processors without any communication. This effect is much more
dramatic if we apply loop distribution once more, this time on the outer
do j loop:\
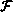 ( A(i-1, j) )
( A(i-1, j) )
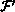 ( A(i, j), B(i, j-1), B(i, j) )
( A(i, j), B(i, j-1), B(i, j) )
*
do j = 2, n
do i = 2, n
A(i, j) =
enddo
enddo
do j = 2, n
do i = 2, n
B(i, j) =
enddo
enddo
MMMMMMMMMMMMMMMMMMMMMMMMMM¯P3. After loop distribution of j loop.
For the same partitioning scheme (i.e., A by column and B by row), we
now need only O(1) communication steps, which occur between the two outer
do j loops. The computation of A in the first loop can be done in
parallel by all processors, since all dependences within A are internalized
in the partitions. After that, the required communication is performed to
satisfy the value dependence of B on A. Then the computation of B can proceed
in parallel, because all dependences within B are internalized in the
partitions. The absence of any communication within the loops considerably
improves efficiency.
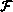 ( A(i-1, j) )
( A(i-1, j) )
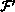 ( A(i, j), B(i, j-1), B(i, j) )
( A(i, j), B(i, j-1), B(i, j) )
Currently, the tool provides a menu of several program transformations, and the programmer can choose which one to apply. When a particular transformation is chosen by the programmer, the tool responds by automatically performing the transformation on the program segment, and updating all internal information automatically.