




Perhaps the most significant and influential parallel computer system
of the early 1980s was the Caltech Cosmic Cube
[Seitz:85a], developed by Charles Seitz and Geoffrey Fox. Since
it was the inspiration for the C P project, we describe it and its
immediate successors in some detail
[Fox:87d;88oo], [Seitz:85a].
P project, we describe it and its
immediate successors in some detail
[Fox:87d;88oo], [Seitz:85a].
The hypercube work at Caltech originated in May 1981 when, as
described in Chapter 1, Fox attended a seminar by Carver Mead
on VLSI and its implications for concurrency. As described
in more detail in Sections 4.1 and 4.3, Fox realized that
he could use parallel computers for the lattice gauge computations that were central to his research at the time and
that his group was running on a VAX 11/780. During the summer of 1981,
he and his students worked out an algorithm that he thought would be
parallel and tried it out on his VAX (simulating parallelism). The
natural architecture for the problems he wanted to compute was
determined to be a 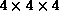 three-dimensional grid, which
happens to be 64 processors (Figure 4.3).
three-dimensional grid, which
happens to be 64 processors (Figure 4.3).
In the fall of 1981 Fox approached Chuck Seitz about building a suitable computer. After an exchange of seminars, Seitz showed great interest in doing so and had funds to build a hypercube. Given Fox's problem, a six-dimensional hypercube (64 processors) was set as the target. Memory size of 128K was chosen after some debate; applications people (chiefly Fox) wanted at least that much. A trade-off was made between the number of processors and memory size. A smaller cube would been built if larger memory had been chosen.
From the outset a key goal was to produce an architecture with interprocessor communications that would scale well to a very large number of processors. The features that led to the choice of the hypercube topology specifically were the moderate growth in the number of channels required as the number of processors increases, and the good match between processor and memory speeds because memory is local.
The Intel 8086 was chosen because it was the only microprocessor available at the time with a floating-point co-processor, the 8087. First, a prototype 4-node system was built with wirewrap boards. It was designed, assembled, and tested during the winter of 1981-82. In the spring of 1982, message-passing software was designed and implemented on the 4-node. Eugene Brooks' proposal of simple send/receive routines was chosen and came to be known as the Crystalline Operating System (CrOS), although it was never really an operating system.
In autumn of 1982, simple lattice problems were implemented on the 4-node by Steve Otto and others. CrOS and the computational algorithm worked satisfactorily. By January 1983, Otto had the lattice gauge applications program running on the 4-node. Table 4.2 details the many projects and publications stemming from this pioneering work.
With the successful experience on the 4-node, Seitz proceeded to have printed circuit boards designed and built. The 64-node Cosmic Cube was assembled over the summer of 1983 and began operation in October 1983. It has been in use ever since, although currently it is lightly used.
The key characteristics of the Cosmic Cube are that it has 64 nodes,
each with an 8086/8087, 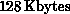 of memory, and communication
channels with 2 Mbits/sec peak speed between nodes (about 0.8 Mbits/sec
sustained in one direction). It is five feet long, six cubic feet in volume,
and draws 700 watts.
of memory, and communication
channels with 2 Mbits/sec peak speed between nodes (about 0.8 Mbits/sec
sustained in one direction). It is five feet long, six cubic feet in volume,
and draws 700 watts.
The Cosmic Cube provided a dramatic demonstration that multicomputers could be built quickly, cheaply, and reliably. In terms of reliability, for example, there were two hard failures in the first 560,000 node hours of operation-that is, during the first year of operation. Its performance was low by today's standards, but it was still between five and ten times the performance of a DEC VAX 11/780, which was the system of choice for academic computer departments and research groups in that time period. The manufacturing cost of the system was $80,000, which at that time was about half the cost of a VAX with a modest configuration. Therefore, the price performance was on the order of 10 to 20 times better than a VAX 780. This estimate does not take into account design and software development costs; on the other hand, it was a one-of-a-kind system, so manufacturing costs were higher than for a commercial product. Furthermore, it was clearly a scalable architecture, and that is perhaps the most important feature of that particular project.
In the period from October, 1983 to April, 1984 a 2500-hour run of a QCD problem (Table 4.1) was completed, achieved 95% efficiency, and produced new scientific results. This demonstrated that hypercubes are well-suited for QCD (as are other architectures).
As described in Section 1.3, during the fall of 1982 Fox surveyed many
colleagues at Caltech to determine whether they needed large-scale
computation in their research and began to examine those applications for
suitability to run on parallel computers. Note that this was before the
64-node Cosmic Cube was finished, but after the 4-node gave evidence that
approach was sound. The Caltech Concurrent Computation Program (C P) was
formed in Autumn of 1982. A decision was made to develop big, fast hypercubes
rather than rely on Crays. By the summer of 1984, the ten applications
of Table 4.2 were running on the Cosmic Cube [Fox:87d].
P) was
formed in Autumn of 1982. A decision was made to develop big, fast hypercubes
rather than rely on Crays. By the summer of 1984, the ten applications
of Table 4.2 were running on the Cosmic Cube [Fox:87d].
Two key shortcomings that were soon noticed were that too much time was spent in communications and that high-speed external I/O was not available. The first was thought to be addressable with custom communication chips.
In the summer of 1983, Fox teamed with Caltech's Jet Propulsion
Laboratory (JPL) to build bigger and better hypercubes. The first was
the Mark II, still based on 8086/8087 (no co-processor faster than 8087
was yet available), but with 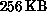 memory, faster communications, and
twice as many nodes. The first 32 nodes began operating in September,
1984. Four 32-node systems and one 128-node were built. The latter
was completed in June, 1985 [Fox:88oo].
memory, faster communications, and
twice as many nodes. The first 32 nodes began operating in September,
1984. Four 32-node systems and one 128-node were built. The latter
was completed in June, 1985 [Fox:88oo].
The Caltech project inspired several industrial companies to build commercial hypercubes. These included Intel, nCUBE [Karplus:87a], Ametek [Seitz:88b], and Floating Point Systems Corporation. Only two years after the 64-node Caltech Cosmic Cube was operational, there were commercial products on the market and installed at user sites.
With the next Caltech-JPL system, the Mark III, there was a switch to the
Motorola family of microprocessors. On each node the Mark III had
one Motorola 68020/68881 for computation and another 68020 for
communications. The two processors shared the 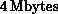 of node
memory. The first 32-node Mark III was operational in April, 1986.
The concept of dedicating a processor to communications
has influenced commercial product design, including recently introduced
systems.
of node
memory. The first 32-node Mark III was operational in April, 1986.
The concept of dedicating a processor to communications
has influenced commercial product design, including recently introduced
systems.
In the spring of 1986, a decision was made to build a variant of the
Mark III, the Mark IIIfp (originally dubbed the Mark IIIe). It was
designed to compete head-on with ``real'' supercomputers. The Mark IIIfp
has a daughter board at each node with the Weitek XL floating-point
chip set running at 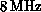 , which gives a peak speed of
, which gives a peak speed of
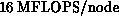 . By January 1987, an 8-node Mark IIIfp was
operational. A 128-node system was built and in the spring of 1989 achieved
. By January 1987, an 8-node Mark IIIfp was
operational. A 128-node system was built and in the spring of 1989 achieved
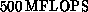 on two applications.
on two applications.
In summary, the hypercube family of computers enjoyed rapid development and was used for scientific applications from the beginning. In the period from 1982 to 1987, three generations of the family were designed, built, and put into use at Caltech. The third generation (the Mark III) even included a switch of microprocessor families. Within the same five years, four commercial vendors produced and delivered computers with hypercube architectures. By 1987, approximately 50 major applications had been completed on Caltech hypercubes. Such rapid development and adaption has few if any parallels. The remaining chapters of this book are largely devoted to lessons from these applications and their followers.