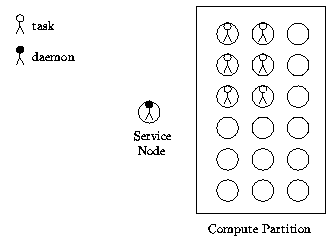
Figure: PVM daemon and tasks on MPP host
A typical MPP system has one or more service nodes for user logins and a large number of compute nodes for number crunching. The PVM daemon runs on one of the service nodes and serves as the gateway to the outside world. A task can be started on any one of the service nodes as a Unix process and enrolls in PVM by establishing a TCP socket connection to the daemon. The only way to start PVM tasks on the compute nodes is via pvm_spawn(). When the daemon receives a request to spawn new tasks, it will allocate a set of nodes if necessary, and load the executable onto the specified number of nodes.
The way PVM allocates nodes is system dependent. On the CM-5, the entire partition is allocated to the user. On the iPSC/860, PVM will get a subcube big enough to accommodate all the tasks to be spawned. Tasks created with two separate calls to pvm_spawn() will reside in different subcubes, although they can exchange messages directly by using the physical node address. The NX operating system limits the number of active subcubes system-wide to 10. Pvm_spawn will fail when this limit is reached or when there are not enough nodes available. In the case of the Paragon, PVM uses the default partition unless a different one is specified when pvmd is invoked. Pvmd and the spawned tasks form one giant parallel application. The user can set the appropriate NX environment variables such as NX_DFLT_SIZE before starting PVM, or he can specify the equivalent command-line arguments to pvmd (i.e., pvmd -sz 32).
Figure: Packing: breaking data into fixed-size fragments
PVM message-passing functions are implemented in terms of
the native send and receive system calls.
The ``address" of a task is encoded in the task id, as illustrated
in Figure ![]() .
.

Figure: How TID is used to distinguish tasks on MPP
This enables the messages to be sent directly to the target task, without any help from the daemon. The node number is normally the logical node number, but the physical address is used on the iPSC/860 to allow for direct intercube communication. The instance number is used to distinguish tasks running on the same node.

Figure: Buffering: buffering one fragment by receiving
task until pvm_recv() is called
PVM normally uses asynchronous send primitives to send
messages.
The operating system can run out of
message handles very quickly if a lot of small messages or several
large messages are sent at once.
PVM will be forced to switch to synchronous send when there are no more
message handles left or when the system buffer gets filled up.
To improve performance, a task
should call pvm_send() as soon as the data becomes available,
so (one hopes) when the other task calls pvm_recv(), the message will
already be in its buffer. PVM buffers one incoming packet between
calls to pvm_send()/pvm_recv(). A large message,
however, is broken up into
many fixed-size fragments during packing, and each piece is sent
separately.
Buffering one of these fragments
is not sufficient unless pvm_send() and pvm_recv() are synchronized.
Figures ![]() and
and ![]() illustrate this process.
illustrate this process.
The front end of an MPP system is treated as a regular workstation. Programs to be run there should be linked with the regular PVM library, which relies on Unix sockets to transmit messages. Normally one should avoid running processes on the front end, because communication between those processes and the node processes must go through the PVM daemon and a TCP socket link. Most of the computation and communication should take place on the compute nodes in order to take advantage of the processing power of these nodes and the fast interconnects between them.
Since the PVM library for the front end is different from the one for the nodes, the executable for the front end must be different from the one compiled for the nodes. An SPMD program, for example, has only one source file, but the object code must be linked with the front end and node PVM libraries separately to produce two executables if it is to be started from the front end. An alternative would be a ``hostless" SPMD program , which could be spawned from the PVM console.
Table ![]() shows the native system calls used by the corresponding
PVM functions on various platforms.
shows the native system calls used by the corresponding
PVM functions on various platforms.
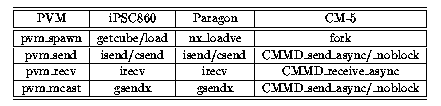
Table: Implementation of PVM system calls
The CM-5 is somewhat different from the Intel systems because it requires a special host process for each group of tasks spawned. This process enrolls in PVM and relays messages between pvmd and the node programs. This, needless to say, adds even more overhead to daemon-task communications.
Another restrictive feature of the CM-5 is that all nodes in the same partition are scheduled as a single unit. The partitions are normally configured by the system manager and each partition must contain at least 16 processors. User programs are run on the entire partition by default. Although it is possible to idle some of the processors in a partition, as PVM does when fewer nodes are called for, there is no easy way to harness the power of the idle processors. Thus, if PVM spawns two groups of tasks, they will time-share the partition, and any intergroup traffic must go through pvmd.
Additionally, CMMD has no support for multicasting. Thus, pvm_mcast() is implemented with a loop of CMMD_async_send().