The layout of matrix blocks in the local memory of a process, and the
arrangement of matrix elements within each block, can also affect
performance. Here, tradeoffs among several factors need to be taken into
account. When communicating matrix blocks, for example in the broadcasts
of ![]() and
and ![]() , we would like the data in each block to be contiguous in
physical memory so there is no need to pack them into a communication
buffer before sending them. On the other hand, when updating the trailing
submatrix, E, each process multiplies a column of blocks by a row of blocks,
to do a rank-r update on the part of E that it contains. If this
were done as a series of separate block-block matrix multiplications, as shown
in Figure 18(a), the
performance would be poor except for sufficiently large block sizes, r,
since the vector and/or pipeline units on most processors would not be
fully utilized, as may be seen in Figure 17 for the i860
processor. Instead, we arrange the loops of the computation as shown
in Figure 18(b).
Now, if the data are laid out in physical memory first
by running over the i index and then over the d index the inner two
loops can be merged, so that the length of the inner loop is now
, we would like the data in each block to be contiguous in
physical memory so there is no need to pack them into a communication
buffer before sending them. On the other hand, when updating the trailing
submatrix, E, each process multiplies a column of blocks by a row of blocks,
to do a rank-r update on the part of E that it contains. If this
were done as a series of separate block-block matrix multiplications, as shown
in Figure 18(a), the
performance would be poor except for sufficiently large block sizes, r,
since the vector and/or pipeline units on most processors would not be
fully utilized, as may be seen in Figure 17 for the i860
processor. Instead, we arrange the loops of the computation as shown
in Figure 18(b).
Now, if the data are laid out in physical memory first
by running over the i index and then over the d index the inner two
loops can be merged, so that the length of the inner loop is now  .
This generally results in much better vector/pipeline performance. The b and
j loops in Figure 18(b) can also be merged,
giving the algorithm shown
in Figure 18(c).
This is just the outer product form of the multiplication of
an
.
This generally results in much better vector/pipeline performance. The b and
j loops in Figure 18(b) can also be merged,
giving the algorithm shown
in Figure 18(c).
This is just the outer product form of the multiplication of
an ![]() by an
by an 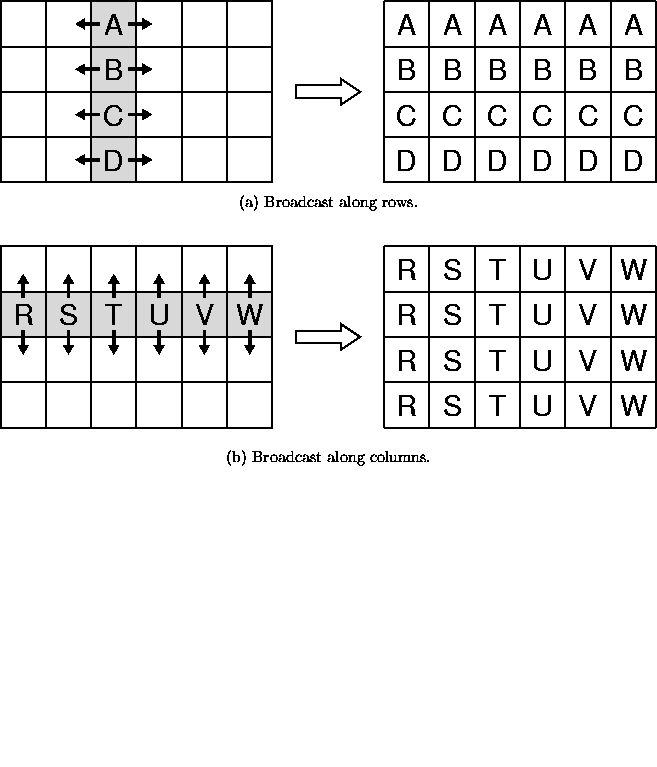 matrix, and would
usually be done by a call to the Level 3 BLAS routine xGEMM of which
an assembly coded sequential version is available on most machines.
Note that in Figure 18(c) the order of the
inner two loops is appropriate for a Fortran implementation - for the C
language this order should be reversed, and the data should be stored in each
process by rows instead of by columns.
matrix, and would
usually be done by a call to the Level 3 BLAS routine xGEMM of which
an assembly coded sequential version is available on most machines.
Note that in Figure 18(c) the order of the
inner two loops is appropriate for a Fortran implementation - for the C
language this order should be reversed, and the data should be stored in each
process by rows instead of by columns.
![]()
Figure 17: Performance of the assembly-coded Level 3 BLAS matrix multiplication
routine
DGEMM on one i860 processor of the Intel Delta system. Results for square
and rectangular matrices are shown. Note that the peak performance of about
35 Mflops is attained only for matrices whose smallest dimension exceeds 100.
Thus, performance is improved if a few large matrices are multiplied by each
process, rather than many small ones.
![]()
Figure 18: Pseudocode for different versions of the rank-r update,
![]() , for one process. The number of row and column blocks
per process is given by
, for one process. The number of row and column blocks
per process is given by ![]() and
and 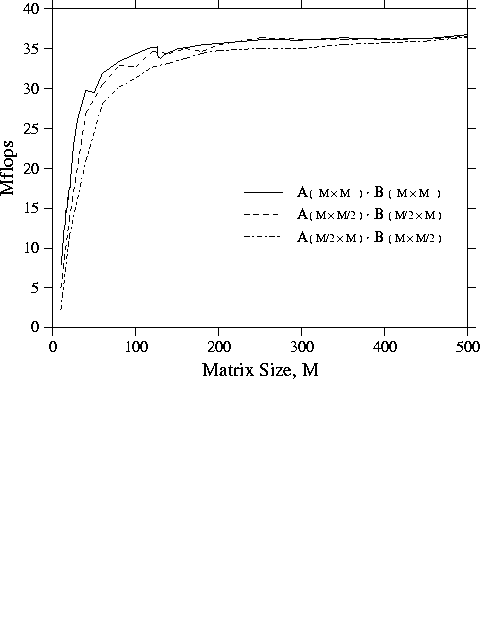 , respectively;
r is the block size. Blocks are indexed by (b,d), and elements
within a block by (i,j). In version (a) the
, respectively;
r is the block size. Blocks are indexed by (b,d), and elements
within a block by (i,j). In version (a) the ![]() blocks are
multiplied one at a time, giving an inner loop of length r. (b) shows the
loops rearranged before merging the i and d loops, and the j and b
loops. This leads to the outer product form of the algorithm shown in (c) in
which the inner loop is now of length .
blocks are
multiplied one at a time, giving an inner loop of length r. (b) shows the
loops rearranged before merging the i and d loops, and the j and b
loops. This leads to the outer product form of the algorithm shown in (c) in
which the inner loop is now of length .
We have found in our work on the Intel iPSC/860 hypercube and the Delta
system that it is better to optimize for the sequential matrix multiplication
with an (i,d,j,b) ordering of memory in each process, rather than
adopting an (i,j,d,b) ordering to avoid buffer copies when communicating
blocks. However, there is another reason for doing this. On most distributed
memory computers the message startup cost is sufficiently large that it is
preferable wherever possible to send data as one large message rather than as
several smaller messages. Thus, when communicating ![]() and
and ![]() the blocks
to be broadcast would be amalgamated into a single message, which requires
a buffer copy. The emerging Message Passing Interface (MPI) standard
[20]
provides support for noncontiguous messages, so in the future the need to avoid
buffer copies will not be of such concern to the application developer.
the blocks
to be broadcast would be amalgamated into a single message, which requires
a buffer copy. The emerging Message Passing Interface (MPI) standard
[20]
provides support for noncontiguous messages, so in the future the need to avoid
buffer copies will not be of such concern to the application developer.