




Next: Software Availability
Up: An Adaptively Blocked Lanczos
Previous: An Adaptively Blocked Lanczos
Contents
Index
The following table summarizes the storage requirements for the
different levels of ABLE.
For clarity, we assume that the block size is a constant, 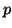 .
To obtain an upper bound for the storage requirements in the variable block
case, replace by the maximum allowed block sizes,
.
To obtain an upper bound for the storage requirements in the variable block
case, replace by the maximum allowed block sizes, 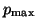 .
.
| Level |
Function |
Storage requirement |
| 1 |
basic three-term recurrences |
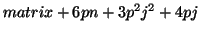 |
| 2 |
full biorthogonality |
additional 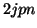 |
| 3 |
semi-biorthogonality |
additional 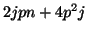 |
| 4 |
treat breakdown or cluster |
no additional requirement |
Note that matrix denotes the required storage for
computing the product 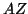 and
and 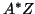 .
.
To maintain full or semi-biorthogonality,
it is necessary to store all computed Lanczos vectors
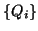 and
and 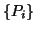 .
The user must allocate memory for two rectangular arrays of dimension
.
The user must allocate memory for two rectangular arrays of dimension
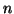 by
by 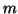 for this purpose. If memory is limited, the best remedy is
to restart as described in [207,110], but this is not
available in the current version of ABLE.
for this purpose. If memory is limited, the best remedy is
to restart as described in [207,110], but this is not
available in the current version of ABLE.
Now, let us summarize the cost of floating point operations
performed per Lanczos step. Lower order floating point operation
costs are ignored. The following table is a summary of the different types of
operations required in the implementation of ABLE.
| |
Matrix- |
m-inner |
m-saxpy |
m-scaling |
|
| Function |
m-vectors |
product |
|
|
QRD |
| |
product |
(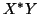 ) ) |
(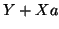 ) ) |
(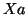 ) ) |
|
| Basic three-term |
2 |
6 |
8 |
2 |
2 |
| fullbo |
|
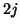 |
|
|
|
| semibo |
|
2 |
|
|
|
Here the m-inner
product, m-saxpy, and m-scaling denote the generalizations of the corresponding
Level 1 BLAS inner product, saxpy and scaling operations to
multiple-vector operations.
As with the storage requirements, for simplicity we assume that the block size
is constant.
The multiple vectors are of dimension 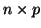 .
The m-inner product, m-saxpy, and m-scaling
involve
.
The m-inner product, m-saxpy, and m-scaling
involve 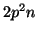 ,
, 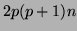 and floating point operations, respectively.
QR decomposition (QRD) of an (
and floating point operations, respectively.
QR decomposition (QRD) of an (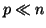 ) matrix costs floating point operations.
Note that for particular problems and data structures,
certain operations can be performed more efficiently.
) matrix costs floating point operations.
Note that for particular problems and data structures,
certain operations can be performed more efficiently.
Additional floating point operations are required for the
following occasional events:
Next: Software Availability
Up: An Adaptively Blocked Lanczos
Previous: An Adaptively Blocked Lanczos
Contents
Index
Susan Blackford
2000-11-20