Clusters, Clouds, and Grids for Scientific Computing
CCGSC 2010
September 7th – 10th, 2010
Highland Lake Inn
Flat Rock, North Carolina

Sponsored by:
![]()



![]()
![]()


![]()
Clusters, Clouds, and Grids for Scientific Computing
2010
Highland Lake Inn
September 7th – 10th, 2010
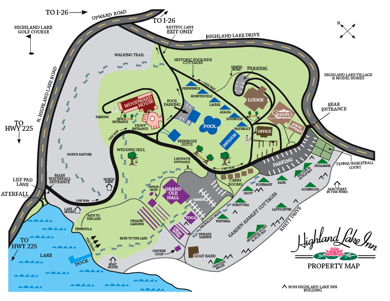
CCGSC 2010 will be held at a resort outside of Asheville, North Carolina called the Highland Lake Inn http://www.hlinn.com/index.html.
The address of the Inn is:
Highland Lake Inn
86
Lilly Pad Lane
Flat Rock, North Carolina 28731
(800) 635-5101 or (828) 693-6812
GPS Coordinates: 35.28297 -82.43367
Go to http://maps.google.com and type in: Highland Lake Rd; Flat Rock, NC or see:
Course map: http://www.cs.utk.edu/~dongarra/ccgsc2010/map1.pdf
Medium map :http://www.cs.utk.edu/~dongarra/ccgsc2010/map2.pdf
Fine map: http://www.cs.utk.edu/~dongarra/ccgsc2010/map3.pdf
Detailed map: http://www.cs.utk.edu/~dongarra/ccgsc2010/map1.pdf
Message from the Program Chairs
This proceeding gathers information about the participants of the Workshop on Clusters, Clouds, and Grids for Scientific Computing that was held at Highland Lake Inn at Flat Rock, North Carolina on September 7 – 10, 2010. This workshop is a continuation of a series of workshops started in 1992 entitled Workshop on Environments and Tools for Parallel Scientific Computing. These workshops have been held every two years and alternate between the U.S. and France. The purpose of this the workshop, which is by invitation only, is to evaluate the state-of-the-art and future trends for cluster computing and the use of computational grids for scientific computing.
This workshop addresses a number of themes for developing and using both cluster and computational grids. In particular, the talks covered:
· Message Passing and High Speed networks
· Grid Infrastructure and Programming Environment
· Cluster Based Computing and Tools
· Languages, Libraries, and Fault Tolerance.
Speakers will present their research in the above four areas and interacted and worked with all the participants on the future software technologies that will provide for easier use of parallel computers.
This workshop was made possible thanks to sponsorship from NSF, Google, AMD, Microsoft Research, The Portland Group, Myricom Inc., and HP, with the scientific support of INRIA (French National Institute for Research in Computer Science), the Electrical Engineering and Computer Science Department of the University of Tennessee in Knoxville (UTK) and University Claude Bernard (UCB-Lyon 1). Thanks!
Jack Dongarra, Knoxville, Tennessee, USA.
Bernard Tourancheau, Lyon, France
CCGSC 2010 Flat Rock NC - Draft agenda (9/12/10 8:07 AM)
September 7th – 10th, 2010
Slides from the meeting are here.
Some pictures from the meeting can be found here.
|
September 7th |
Introduction and Welcome Jack Dongarra, U of Tennessee Bernard Tourancheau, U Lyon |
|
|
6:30 – 7:45 |
Session Chair: Bernard Tourancheau, U Lyon |
Grand Ole Hall (3 talks - 20 minute each) |
|
6:30 |
Patrick Geoffray, Myricom |
The End of HPC |
|
7:00 |
Michael Wolfe, PGI |
Explicit vs. Implicit Programming: Language, Directive, Library |
|
8:00 pm – 9:00 pm |
Dinner |
Low Country Boil at the Pavilion or Grand Ole Hall depending on the weather |
|
9:00 pm - |
Fire Pit and/or Refreshments in Woodward House |
|
|
Wednesday, September 8th |
|
|
|
7:30 - 8:30 |
Breakfast |
Season’s Restaurant |
|
8:30 - 10:35 |
Session Chair: Manish Parashar, Rutgers U |
Grand Ole Hall (5 talks – 25 minutes each) |
|
8:30 |
George Bosilca, UTK |
|
|
8:55 |
Alexey Lastovetsky, University College Dublin |
Design and implementation of parallel algorithms for highly heterogeneous HPC platforms |
|
9:20 |
Joel Saltz, Emory U |
Towards Derivation, Management and Analysis of Exascale Feature Sets |
|
9:45 |
Xingfu Wu, Texas A&M |
Energy and Performance Characteristics of MPI, OpenMP and Hybrid Scientific Applications on Multicore Systems |
|
10:10 |
Nan Boden, Myricom |
|
|
10:35 -11:00 |
Coffee |
Grand Ole Hall |
|
11:00 - 1:05 |
Session Chair: Laurent Lefevre, INRIA/ENS Lyon |
Grand Ole Hall (5 talks – 25 minutes each) |
|
11:00 |
Anthony Danalis, UTK/ORNL |
From Data-Flow to Distributed DAG Scheduling |
|
11:25 |
Christian Obrecht, INSA Lyon |
The TheLMA Project: Multi-GPU Implementation of the Lattice Boltzmann Method |
|
11:50 |
Rajeev Thakur, ANL |
Future Directions in MPI |
|
12:15 |
Rosa Badia, UPC |
Exploiting Multicore Processors and GPUs with OpenMP and OpenCL |
|
12:40 |
Geoffrey Fox, IU |
MPI and MapReduce |
|
1:05 - 2:00 |
Lunch |
Season’s Restaurant |
|
2:00 – 4:30 |
Free time |
|
|
4:30 – 5:00 |
Coffee |
Grand Ole Hall |
|
5:00 – 5:25 |
Tony Hey, Microsoft |
Data Services for Scientific Computing |
|
5:25 - 7:30 |
Panel Chair: Bill Gropp, UIUC |
Grand Ole Hall (Panel Session) |
|
|
Pete Beckman, ANL/UC |
Panel on “Igniting Exascale Computing” |
|
|
Franck Cappello, INRIA/UIUC |
|
|
|
Al Geist, ORNL |
|
|
|
Satoshi Matsuoka, TiTech |
|
|
|
Thomas Sterling, LSU |
|
|
8:00 – 9:00 |
Dinner |
Season’s Restaurant |
|
9:00 pm - |
Fire Pit and/or Refreshments in Woodward House |
|
|
Thursday, September 9th |
|
|
|
7:30 - 8:30 |
Breakfast |
Season’s Restaurant |
|
8:30 - 10:35 |
Session Chair: Thierry Priol, INRIA |
Grand Ole Hall (5 talks – 25 minutes each) |
|
8:30 |
Laurent Lefevre, INRIA/ENS Lyon |
Applying Green solutions in Grids, Clouds and Networks |
|
8:55 |
Ewa Deelman, ISI |
Scientific Workflows and Cloud Computing |
|
9:20 |
Martin Swany, U Delaware |
Shining a light on the I/O problem |
|
9:45 |
Yves Robert, ENS, Lyon |
Checkpointing vs. Migration for Post-Petascale Supercomputers |
|
10:35 -11:00 |
Coffee |
Grand Ole Hall |
|
11:00 - 1:05 |
Session Chair: Jeff Vetter, ORNL/GATech |
Grand Ole Hall (5 talks – 25 minutes each) |
|
11:00 |
Phil Papadopoulos, SDSC |
Making clouds feel more like clusters. Cluster extension into EC2 and remote control of Rocks-hosted virtual clusters |
|
11:25 |
Satoshi Sakiguchi, Grid Tech Research |
High performance GIS and GEO Grid |
|
11:50 |
Anne Benoit, ENS Lyon |
Performance and energy optimization of concurrent pipelined applications |
|
12:15 |
Christine Morin, INRIA |
XtreemOS European Project: Achievements and Perspectives |
|
12:40 |
Jim Plank, UTK |
Storage as a First Class Citizen in HPC Environments |
|
1:05 - 2:00 |
Lunch |
Lunch at Grand Ole Hall |
|
2:00 – 4:00 |
Free time |
|
|
4:00 – 5:00 |
Coffee |
Grand Ole Hall |
|
5:00 - 7:30 |
Session Chair: Andrew Lumsdaine, IU |
Grand Ole Hall (6 talks – 25 minutes each) |
|
5:00 |
Kirk Cameron, VTech |
Implications of SpecPower and the Green500 for HPC |
|
5:25 |
Andrew Lumsdaine, IU |
AM++: A Generalized Active Message Framework for Data-Driven Problems |
|
5:50 |
Duane Merrill, U Virginia |
Efficiently Implementing Dynamic Parallelism for GPUs |
|
6:15 |
Jeff Hollingsworth, UM |
Friends Don't Let Friends Tune Code |
|
6:40 |
Rich Vuduc, GATech |
Should I port my code to a GPU? |
|
7:05 |
David Konerding, Google |
Learning to think like a vertex, a column, and a parallel collection |
|
8:00 – 9:00 |
Dinner |
Season’s Restaurant |
|
9:00 pm - |
Fire Pit and/or Refreshments in Woodward House |
|
|
Friday, September 10th |
|
|
|
7:30 - 8:30 |
Breakfast |
Season’s Restaurant |
|
8:30 - 10:35 |
Session Chair: Vaidy Sunderam, Emory U |
Grand Ole Hall (5 talks – 25 minutes each) |
|
8:30 |
Thilo Kielmann, Vrije U |
Bag-of-Tasks Scheduling under Time and Budget Constraints |
|
8:55 |
Jelena Pjesivac-Grbovic, Google |
10,000 ft view of Google's Cloud |
|
9:20 |
Shirley Moore, UTK |
Hardware Performance Monitoring in the Clouds |
|
9:45 |
Manish Parashar, Rutgers |
Exploring the Role of Clouds in Computational Science and Engineering |
|
10:10 |
Hans Zima, Caltech |
Enhancing the Dependability of Extreme-Scale Applications |
|
10:35 -11:00 |
Coffee |
Grand Ole Hall |
|
11:00 - 1:05 |
Session Chair: Tahar Kechadi, UCD |
Grand Ole Hall (4 talks – 30 minutes each) |
|
11:00 |
Padma Raghavan, Penn St. |
Optimizing Scientific Software for Multicores |
|
11:25 |
David Walker, Cardiff U |
Automatic Generation of Portals for Distributed Scientific Applications |
|
11:50 |
Emmanuel Jeannot, Loria INRIA-Lorraine |
Near-Optimal Placement of MPI processes on Hierarchical NUMA Architectures |
|
12:15 |
David Bader, GATech |
Massive-scale analysis of streaming social networks |
|
1:05 - 2:00 |
Lunch |
BBQ at the Pavilion or Season’s Restaurant |
|
2:00 |
Depart |
|
Attendee List
|
Wes |
Alvaro |
UTK |
|
David |
Bader |
GATech |
|
Rosa |
Badia |
BSC |
|
Pete |
Beckman |
ANL |
|
Anne |
Benoit |
ENS Lyon |
|
Nan |
Boden |
Myricom |
|
George |
Bosilca |
UTK |
|
Aurelien |
Bouteiller |
UTK |
|
Bill |
Brantley |
AMD |
|
Kirk |
Cameron |
VT |
|
Franck |
Cappello |
INRIA/UIUC |
|
Anthony |
Danalis |
UTK/ORNL |
|
Ewa |
Deelman |
ISI |
|
Jack |
Dongarra |
UTK/ORNL |
|
Peng |
Du |
UTK |
|
Geoffrey |
Fox |
IU |
|
Al |
Geist |
ORNL |
|
Patrick |
Geoffray |
Myricom |
|
Bill |
Gropp |
UIUC |
|
Thomas |
Herault |
UTK |
|
Tony |
Hey |
Microsoft |
|
Jeff |
Hollingsworth |
U Maryland |
|
Heike |
Jagode |
UTK |
|
Emmanuel |
Jeannot |
INRIA |
|
Tahar |
Kechadi |
UCD |
|
Thilo |
Kielmann |
Vrije Universiteit |
|
David |
Konerding |
|
|
Jakub |
Kurzak |
UTK |
|
Alexey |
Lastovetsky |
U College Dublin |
|
Laurent |
Lefevre |
INRIA/ENS-Lyon |
|
Andrew |
Lumsdaine |
Indiana |
|
Piotr |
Luszczek |
UTK |
|
Satoshi |
Matsuoka |
Tokyo Institute of Technology |
|
Duane |
Merrill |
U of Virginia |
|
Terry |
Moore |
UTK |
|
Shirley |
Moore |
UTK |
|
Christine |
Morin |
INRIA |
|
Christian |
Obrecht |
Centre de Thermique de Lyon |
|
Phil |
Papadopoulos |
UC San Diego |
|
Manish |
Parashar |
Rutgers U |
|
Jelena |
Pjesivac-Grbovic |
|
|
Jim |
Plank |
UTK |
|
Thierry |
Priol |
INRIA |
|
Irene |
Qualters |
NSF |
|
Padma |
Raghavan |
Penn State |
|
Yves |
Robert |
ENS Lyon |
|
Joel |
Saltz |
Emory U |
|
Jennifer |
Schopf |
NSF |
|
Satoshi |
Sekiguchi |
AIST |
|
Fengguang |
Song |
UTK |
|
Thomas |
Sterling |
LSU |
|
Vaidy |
Sunderam |
Emory U |
|
Martin |
Swany |
U Delaware |
|
Rajeev |
Thakur |
ANL |
|
Bernard |
Tourancheau |
University Lyon |
|
Jeff |
Vetter |
ORNL/GATech |
|
Xavier |
Vigouroux |
Bull |
|
Rich |
Vuduc |
GATech |
|
David |
Walker |
Cardiff U |
|
Vince |
Weaver |
UTK |
|
Michael |
Wolfe |
PGI |
|
Xingfu |
Wu |
Texas A&M |
|
Asim |
YarKhan |
UTK |
|
Hans |
Zima |
Caltech |
Arrival / Departure Information
|
|
|
Arrivals |
Departures |
|
Wes |
Alvaro |
9/7 drive |
|
|
David |
Bader |
9/8 drive |
|
|
Rosa |
Badia |
9/6 5:55 pm DL 4990 |
9/10 2:05 pm DL 5398 |
|
Pete |
Beckman |
9/7 3:51 pm UN 6340 |
9/10/10 4:17 pm UN 6340 |
|
Anne |
Benoit |
9/7 3:15 rent a car DL 5091 |
|
|
Nan |
Boden |
Patrick to pick up |
|
|
George |
Bosilca |
9/7 drive |
|
|
Aurelien |
Bouteiller |
9/7 drive |
|
|
Bill |
Brantley |
9/7 12:30 pm rent a car |
9/10 4pm |
|
Kirk |
Cameron |
9/7 drive |
|
|
Franck |
Cappello |
9/7 drive |
|
|
Anthony |
Danalis |
9/7 drive |
|
|
Ewa |
Deelman |
9/7 3:51 pm UN 6340 |
9/9 4:17 pm UN 6340 |
|
Jack |
Dongarra |
9/6 drive |
|
|
Peng |
Du |
9/7 drive |
|
|
Geoffrey |
Fox |
9/7 4:11 pm DL 5602 |
9/10 3:15 pm DL 5091 |
|
Al |
Geist |
9/7 drive |
|
|
Patrick |
Geoffray |
Drive |
|
|
Bill |
Gropp |
9/7 drive |
|
|
Thomas |
Herault |
9/7 drive |
|
|
Tony |
Hey |
9/7 5:26 pm DL 6306 |
9/10 6:50p pm DL 5280 |
|
Jeff |
Hollingsworth |
9/7 3:01 pm US 2273 |
9/10 11:45 LV CLT US 2236 |
|
Heike |
Jagode |
9/7 drive |
10-Sep |
|
Emmanuel |
Jeannot |
9/7 5:47 pm DL 5549 |
9/10 2:05 pm |
|
Tahar |
Kechadi |
9/7 4:43 pm CO 2299 ride w/Walker |
9/10 5:15 pm CO 2290 |
|
Thilo |
Kielmann |
9/6 7:21 pm US 3905 |
9/10 4:05 pm US 4278 |
|
David |
Konerding |
9/7 3:51 pm UN 6340 |
|
|
Jakub |
Kurzak |
9/7 drive |
|
|
Alexey |
Lastovetsky |
9/7 4:43 pm CO 2299 ride w/Walker |
9/10 5:15 pm CO 2290 |
|
Laurent |
Lefevre |
9/7 3:15 rent a car DL 5091 |
|
|
Andrew |
Lumsdaine |
9/7 3:54 pm DL 3909 |
9/10 4:36 pm DL 5602 |
|
Piotr |
Luszczek |
9/7 drive |
|
|
Satoshi |
Matsuoka |
9/8 around 4:30 pm |
|
|
Duane |
Merrill |
9/7 drive |
|
|
Terry |
Moore |
9/6 drive |
|
|
Shirley |
Moore |
9/7 drive |
|
|
Christine |
Morin |
9/7 5:47 pm DL 5549 (Priol to pickup) |
9/10 6:17 pm |
|
Christian |
Obrecht |
9/7 drive |
9/10 5:17 pm DL 5549 |
|
Phil |
Papadopoulos |
9/7 5:47 pm DL 5549 |
9/10 4:36 pm DL 5602 |
|
Manish |
Parashar |
9/7 6:09 pm US 3752 |
9/10 5:15 pm CO 2290 |
|
Jelena |
Pjesivac-grbovic |
9/7 5:47 pm DL 5549 |
9/10 4:35 pm DL 5602 |
|
Jim |
Plank |
9/7 drive |
|
|
Thierry |
Priol |
9/6 drive late arrival |
9/10 6:17 pm |
|
Irene |
Qualters |
9/7 drive |
|
|
Padma |
Raghavan |
9/7 1:57pm US 3617 |
9/10 4:05 pm |
|
Yves |
Robert |
9/7 3:15 rent a car DL 5091 |
9/10 3:25 pm DL 5546 |
|
Joel |
Saltz |
9/7 drive in time for dinner |
|
|
Jennifer |
Schopf |
9/7 3:34 pm US 4495 |
9/10 2:24 pm US 3617 |
|
Satoshi |
Sekiguchi |
9/7 3:51 pm UN 6340 |
9/10 4:17 pm UN 6340 |
|
Fengguang |
Song |
9/7 drive |
|
|
Thomas |
Sterling |
9/7 1:52 pm Charlotte |
9/10 4:35 pm Charlotte |
|
Vaidy |
Sunderam |
9/8 1:40 pm DL 5168 |
9/10 4:36 pm DL 5602 |
|
Martin |
Swany |
9/7 2:40 pm DL 1247 has a car |
9/10 3:20 pm DL 2359 |
|
Rajeev |
Thakur |
9/7 3:51pm UN 6340 |
9/10 4:17 pm UN 6340 |
|
Bernard |
Tourancheau |
9/7 drive |
9/10 5:17 pm DL 5549 |
|
Jeff |
Vetter |
|
|
|
Xavier |
Vigouroux |
9/7 drive from Charlotte |
9/10 |
|
Rich |
Vuduc |
9/7 drive |
request 2 room cabin |
|
David |
Walker |
9/7 4:43 rent a car CO 2299 |
|
|
Vince |
Weaver |
9/7 drive |
|
|
Michael |
Wolfe |
9/7 4:11 pm DL 5602 |
9/10 3:15 pm DL 5091 |
|
Xingfu |
Wu |
9/7 4:38 pm CO 2380 |
9/10 5:15 pm CO 2258 |
|
Hans |
Zima |
9/7 3:51 pm UN 6340 |
9/10 4:17 pm UN 6340 |
If you need a taxi or limo from the airport in Asheville, here are some numbers:
|
Company |
Telephone |
Rate |
|
Carolina Limousine |
828-258-2526 |
$100. |
|
Carolina Taxi & Industrial Transportation |
828-693-3221 |
$36. |
|
Elite Limousine |
828-890-2424 |
$70. |
|
Metro Cab |
828-254-1155 |
$45. |
|
New Bluebird Taxi |
828-258-8331 |
$100. |
|
Pegasus Transportation |
828-281-4600 |
$75. |
|
Starlite Limousine |
828-586-5466 |
$75/hour |
|
Yellow Cab Taxi Company |
828-253-3311 |
$92. |
Abstracts
David Bader, GATech
Massive-scale analysis of streaming social networks
Emerging real-world graph problems include detecting community structure in large social networks, improving the resilience of the electric power grid, and detecting and preventing disease in human populations. Unlike traditional applications in computational science and engineering, solving these problems at scale often raises new challenges because of sparsity and the lack of locality in the data, the need for additional research on scalable algorithms and development of frameworks for solving these problems on high performance computers, and the need for improved models that also capture the noise and bias inherent in the torrential data streams. The explosion of real-world graph data poses a substantial challenge: How can we analyze constantly changing graphs with billions of vertices? Our approach leverages the Cray XMT's fine-grained parallelism and flat memory model to scale to massive graphs. On the Cray XMT, our static graph characterization package GraphCT summarizes such massive graphs, and our ongoing STINGER streaming work updates clustering coefficients on massive graphs at a rate of tens of thousands updates per second.
Rosa Badia, BSC
Exploiting Multicore Processors and GPUs with OpenMP and OpenCL
With the appearance of multicore processors, considering between them GPUs and other accelerator devices, multiple programming models have been appearing. However, it is important to be able to propose approaches that enable a seamless integration of the applications with the different devices, without a need for rewriting applications each time. We present OpenMPT, a programming model based on OpenMP and StarSs, and that can also incorporate the use of OpenCL or CUDA kernels.
From OpenMP we obtain high expressiveness to exploit parallelism using tasks. StarSs extensions allow runtime dependence analysis between tasks, and data transfers. And OpenCL and CUDA allow the programmer to easily write efficient and portable SIMD kernels to be exploited inside the tasks. We evaluate the proposal on three different architectures, SMP, Cell/B.E. and GPUs, showing the wide usefulness of the approach. The evaluation is done with four different benchmarks, Matrix Multiply, BlackScholes, Perlin Noise, and Julia Set. We compare the results obtained with the execution of the same benchmarks writtenin OpenCL, in the same architectures. The results show that OpenMPT greatly outperforms the OpenCL environment. It is more flexible to exploit multiple accelerators. And due to the simplicity of the annotations, it increases programmer’s productivity.
Anne Benoit, ENS Lyon and Institut Universitaire de France
(Joint work with Paul Renaud-Goud and Yves Robert)
Performance and energy optimization of concurrent pipelined applications
In this talk, we study the problem of finding optimal mappings for several independent but concurrent linear chain workflow applications, in order to optimize performance-related criteria together with energy consumption. The goal is to select an execution speed for each processor, and then to assign application stages to processors, with the aim of optimizing several concurrent optimization criteria. There is a clear trade-off to reach, since running faster and/or more processors leads to better performance, but the energy consumption is then very high. Energy savings can be achieved at the price of a lower performance, by reducing processor speeds or enrolling fewer resources. We establish the complexity of several multi-criteria optimization problems, whose objective functions combine period, latency and energy criteria. We demonstrate the difficulty of performance/energy trade-offs by proving that the tri-criteria problem is NP-hard, even with a single application on a fully homogeneous platform. On the experimental side, we design polynomial-time heuristics, and assess their absolute performance thanks to a linear program. One main goal is to evaluate the impact of processor sharing on the quality of the solution.
Kirk Cameron, Virginia Tech
Implications of SpecPower and the Green500 for HPC
The SPECpower benchmark and the Green500 list make it possible to track energy-efficiency gains in both servers and supercomputers. In this talk we discuss what we have learned in the three years since first release of these two energy efficiency lists including trends and implications for HPC systems and applications.
Anthony Danalis, UTK/ORNL
From Data-Flow to Distributed DAG Scheduling
And here is my abstract: In recent years, several research projects have put a significant effort toward micro-task scheduling using Directed Acyclic Graphs (DAGs) to express dependencies between tasks. While this approach has been, so far, mostly successful in shared memory system, extending DAG scheduling to the distributed world is of great interest to the research community. DAGuE is an ICL developed generic framework for architecture aware scheduling and management of micro-tasks on distributed many-core heterogeneous architectures. In this talk, I will describe the symbolic internal representation of the DAG used by this system, and explain how it enables dynamic and fully distributed task scheduling. I will describe the process followed to generate the task-dependency symbolic representation from the data-dependencies of an annotated serial code input, discuss the limitations of the approach, as well as workarounds, and future plans.
Ewa Deelman, ISI
Scientific Workflows and Cloud Computing
This talk will explore the potential benefits of cloud computing for scientific workflow applications. It will present the performance and cost of clouds from the perspective of three different scientific workflow applications. We will show experiments of running these workflows on a commercial cloud and on a typical HPC system, and we analyze the various costs associated with running those workflows in the cloud. Particular emphasis will be given to issues of data management in cloud environments. In grids and clusters, workflow data is often stored on network and parallel file systems. In this talk we investigate some of the ways in which data can be managed for workflows in the cloud. We discuss various storage and file systems options and analyze the resulting performance and cost of the workflows.
Geoffrey Fox, Indian University
MPI and MapReduce
We compare the functionality and performance of MPI and MapReduce identifying application characteristics that fit these programming models. We describe a family of programming environments/runtimes that interpolate between MPI and MapReduce and so between performance, fault-tolerance and flexibility. The analysis is illustrated with various performance measurements.
Patrick Geoffray, Myricom
The End of HPC
Tony Hey, Microsoft
Data Services for Scientific Computing
Scientific discovery is becoming increasingly driven by data collection, data access, and data analysis. We are also seeing acceleration in the movement of these functions from desktops, laptops, and isolated laboratories to supercomputers, clusters, and the cloud. This is occurring because of the dramatic increase in the amount of data being collected, the complexity of data, the storage space available, our desire to collaborate and share data, and the processing power available to process the data. Cloud computing allows scientists the economic reality and the technical capability to provide the foundational data services critical to future scientific discovery. This talk presents some of our recent experiences on the TeraPixel Project and MODISAzure in leveraging the data services and Cloud Computing.
Jeff Hollingsworth, U of Maryland
Friends Don't Let Friends Tune Code
Tuning code for a specific system has often been necessary, but rarely enjoyable or easy. With many variants of a given architecture now being used in machines, for example the many implementations of the x86 instruction set, tuning has become even more difficult. In this talk, I will outline our work on the Active Harmony Auto-tuning system. I will present some results showing that we can improve the performance of real codes, and that the best configuration can vary quite a bit even among very similar CPUs.
Emmanuel Jeannot, LABRI
Near-Optimal Placement of MPI processes on Hierarchical NUMA Architectures
MPI process placement can play a deterministic role concerning the application performance. This is especially true with nowadays architecture (heterogenous, multicore with different level of caches, etc.). In this paper, we will describe a novel algorithm called TreeMatch that maps processes to resources in order to reduce the communication cost of the whole application. We have implemented this algorithm and will discuss its performance using simulation and on the NAS benchmarks.
Thilo Kielmann, Vrije Universiteit
Bag-of-Tasks Scheduling under Time and Budget Constraints
Commercial cloud offerings, such as Amazon’s EC2, let users allocate compute resources on demand, charging based on reserved time intervals. While this gives great flexibility to elastic applications, users lack guidance for choosing between multiple offerings, in order to complete their computations within given time and budget constraints. In this talk, we present BaTS, our budget and time-constrained scheduler. BaTS can schedule large bags of tasks onto multiple clouds with different CPU performance and cost, minimizing completion time while respecting an upper bound fore budget to be spent. BaTS requires no a-priori information about task completion times, and learns task completion time distributions at run time.
David Konerding, Google
Learning to think like a vertex, a column, and a parallel collection
In the years since the original MapReduce, GFS, and BigTable papers were published, the high performance data processing community has adopted these models for data-intensive computing with great success. Google has continued developing new technologies for rapid analysis of web-scale datasets. In this talk, we introduce recently published technologies: FlumeJava, Pregel, and Dremel, which we believe will have a similar impact. We will describe the programming models, data models, and the requirement to 'think like a vertex, a column, and a parallel collection' to successfully adopt these approaches.
Alexey Lastovetsky, University College Dublin
Design and implementation of parallel algorithms for highly heterogeneous HPC platforms
The current trend in HPC platforms is that they employ increasingly heterogeneous processing units, the relative speeds of which cannot be accurately represented by positive constants independent on the problem size. Therefore, traditional heterogeneous parallel algorithms based on the constant performance models (CPMs) become less and less applicable on these platforms. In this talk, we introduce the functional performance model (FPM) and FPM-based partitioning algorithms proposed to address this issue. The FPM represents the speed of a processing unit by a function of problem size. We show that FPM-based algorithms significantly outperform their CPM-based counterparts on highly heterogeneous platforms given the full FPM of the processing units is provided as an input parameter. While useful in many applications, these algorithms cannot be directly used in self-adaptable applications due to a very high cost of construction of the full FPMs. For self-adaptable applications, we propose a special class of FPM-based algorithms that do not require the FPM as input parameter. Instead, they build a partial estimate of the FPM during their execution and use this estimate for sub-optimal distribution of computations. We present results of experiments with self-adaptable FPM-based applications on various heterogeneous platforms and compare their performance with traditional CPM-based applications
Laurent Lefevre, INRIA/ENS-Lyon
Applying Green solutions in Grids, Clouds and Networks
This talk will discuss some issues on energy efficiency in large scale systems and present some solutions combined with large scale energy monitoring.
Andrew Lumsdaine, Indiana University
AM++: A Generalized Active Message Framework for Data-Driven Problems
The scope of scientific computing continues to grow and now includes diverse application areas such as network analysis, combinatorial computing, knowledge discovery, to name just a few. Large problems in these application areas require HPC resources, but they exhibit computation and communication patterns that are irregular, fine-grained, and non-local, making it difficult to apply traditional HPC approaches to achieve scalable solutions. In this paper we present AM++, a user-level active message library developed explicitly to enable the development of scalable software for these emerging application areas. Our library allows message handlers to be run in an explicit loop that can be optimized and vectorized by the compiler and that can also be executed in parallel on multicore architectures. Runtime optimizations, such as message combining and filtering, are also provided by the library, removing the need to implement that functionality at the application level. Evaluation of AM++ with distributed-memory graph algorithms shows the usability benefits provided by these library features, as well as their performance advantages.
Duane Merrill, U of Virginia
Efficiently Implementing Dynamic Parallelism for GPUs
Compared to traditional and many-core CPU architectures, GPUs are perceived as challenging environments for implementing dynamic, irregular, and nested parallelism. The efficient management of such ad hoc concurrency is necessary for parallelizing many fundamental primitives that have not previously been shown to match the GPU machine model, e.g., sorting, graph traversal, and search space exploration. In this presentation, we discuss our current research into design patterns and idioms for constructing high performance solutions for such dynamic problems. Our recent sorting results are quite promising: we demonstrate GPU sorting rates that exceed 1.0 billion 32-bit keys per second (and over 770 million key-value pairs per second), significantly faster than current CPU-based architectures (including the 32-core Intel Knights-Ferry/Larrabee). As part of this talk, we will present both our design strategies (namely kernel fusion, warp-synchronous programming, flexible granularity via meta-programming, and algorithm serialization) as well as the forward-looking challenges that these techniques place upon the evolution and durability of the stream programming model.
Shirley Moore, UTK
Hardware Performance Monitoring in the Clouds
This talk will address the problem of hardware performance monitoring in virtualized execution environments. In a virtualized environment, application programs run inside virtual machines. A virtual machine monitor (VMM) exports a set of virtual machines to the guest operating systems and manages access to the underlying shared hardware resources. In high performance computing, the performance monitoring units (PMUs) available on modern microprocessors are highly useful for modeling and tuning application performance. Currently available virtualization engines do not virtualize the performance modeling hardware and thus do not provide the necessary support for direct hardware performance monitoring at the application level. A few performance tools have been able to implement limited hardware performance monitoring in some kinds of virtualized environments but require special privileges, provide only system-wide monitoring, or require that the processor timestamp counter not be virtualized. A number of questions arise concerning how to properly virtualize the performance monitoring hardware, such as the exact place to save and restore the MSRs. This talk will survey existing attempts at hardware performance monitoring in virtual environments, discuss open issues, and describe future plans for development of PAPI-V (PAPI-Virtual).
Christine Morin, INRIA Rennes
XtreemOS European Project: Achievements and Perspectives
XtreemOS European project has been funded by the European Commission during the last four years. As part of this project, we have designed and implemented a Grid distributed operating system, called XtreemOS.
The XtreemOS operating system provides for Grids what a traditional operating system offers for a single computer: abstraction from the hardware and secure resource sharing between different users. When a user runs an application on XtreemOS, the operating system automatically finds all resources necessary for the execution, configures user’s credentials on the selected resources and starts the application. It simplifies the work of users by giving them the illusion of using a traditional computer. XtreemOS is a Linux based open source software available for PC, clusters and mobile devices.
In this talk, we will present some innovative XtreemOS features, focusing mainly on the XtreemGCP service implementing fault tolerance for Grid applications. While originally designed as a Grid system, XtreemOS constitutes a sound basis to manage cloud federations. We will then describe our research directions in the area of cloud computing that we will be further investigated in the framework of the Contrail European project starting in October 2010.
Christian Obrecht, Centre de Thermique de Lyon
The TheLMA Project: Multi-GPU Implementation of the Lattice Boltzmann Method
The lattice Boltzmann method (LBM) is a novel approach in computational fluid dynamics, with numerous convenient features from a numerical and physical standpoint, such as explicitness or ability to deal with complex geometries. During the last decade, it has proven to be an effective alternative to the solving of the Navier-Stokes equations. Not the least, the LBM is interesting from the HPC point of view because of its inherent parallelism.
Several successful attempts of implementing the LBM on CUDA enabled GPUs were recently reported; nevertheless these works are of moderate practical impact since memory in existing computing devices is too small for large scale simulations. Multi-GPU implementations of the LBM are still at an early stage of development. In this contribution, we shall present a pthread based multi-GPU LBM solver developed using our TheLMA framework. This program shows excellent performance and scalability. We shall also discuss tiling and communication issues for present and forthcoming implementations.
Phil Papadopoulos, UCSD
Making clouds feel more like clusters. Cluster extension into EC2 and remote control of Rocks-hosted virtual clusters.
Amazon's offering of their simple storage service (S3) and Elastic Compute Cloud (EC2) in 2006 became the catalytic events for the cloud computing "buzz". For any computing system, software configuration and management so that one can assemble working clusters or farms is the first, but critical, step. Fail here and you fail completely. This first step is not an easy one in EC2. Amazon boasts more than 2500 public machine images. A new user must find one that most closely matches their needs and then they must "re-configure" to a system useful to them. Essentially, to effectively use Amazon for real computing loads, significant, time-consuming, and expensive customization is required. One of the barriers to this customization is the ever-growing, ever-changing Amazon API with new terms for old ideas. New interfaces when existing methods should (but do not) work. Basically, a whole new vocabulary and toolset for virtual hardware. Aside from observing the (high) time costs of gaining facility with their implementation, we asked ourselves the basic questions: why doesn't this work more like a cluster? If it really is elastic expansion, why can't I expand my existing cluster using virtual hardware in the cloud? And, finally, why can't I debug from BIOS-level boot in EC2 and make it feel more like my own hardware? After all, in the real world, things do go wrong.
In this talk we'll describe how we use Rocks to robustly author fully-customized, completely reproducible, Amazon-compatible images and some of the war stories needed to make that work. When coupled with Condor, we are able to easily and automatically expand or extend existing local clusters with virtual hardware from EC2. And finally, we'll show our latest work in bringing the concept of full "hardware control" to owners of virtual clusters housed on a Rocks-based physical hosting cluster. Using the Rocks Airboss Service (on the hosting cluster) and Pilot Client (on the laptop), users can have BIOS-level control (power, console) of their virtual cluster from the comfort of their Linux-, Mac-, or Windows-based laptop or workstation
Manish Parashar, Rutgers U
Exploring the Role of Clouds in Computational Science and Engineering
Clouds provide on-demand access to computing utilities, an abstraction of unlimited computing resources, and a usage-based payment model, and are rapidly joining high-performance computing system and Grids as viable platforms for scientific exploration and discovery. In fact, production computational infrastructures are already integrating these paradigms. As a result, understanding application characteristics and usage modes that are meaningful in such a hybrid infrastructure, and how application workflows can effectively utilize it, is critical. In this talk, I will explore the role of clouds (along with traditional HPC) in science and engineering. I will also describe how science and engineering applications with non-trivial requirements can benefit from clouds. This talk is based on research that is part of the CometCloud project at the Center for Autonomic Computing at Rutgers.
Jim Plank, U of Tennessee
Storage as a First Class Citizen in HPC Environments
We understand RAM. We understand disks. We kind of understand SSD's. And we're really good at combining computational elements to get flashy performance numbers. However, we have no idea how storage really fits into high performance computing environments. After 20+ years of working in the areas of fault-tolerance, storage and computation, the speaker will give his perspective on why storage is a second class citizen in HPC environments, and why that should change.
Padma Raghavan, Pennsylvania State University
Optimizing Scientific Software for Multicores
Increasing core counts and decreasing feature sizes of current and future processors pose several challenges for the energy-aware tuning of scientific codes for high performance and reliability. We present some recent work on the modeling of cache and memory subsystem performance of scientific codes and the impact of soft errors on the performance on linear algebra kernels. We conclude with an overview of some energy-aware approaches to ensure reliability and high performance for such scientific kernels.
Yves Robert, ENS Lyon and Institut Universitaire de France
(Joint work with Franck Cappello and Henri Casanova)
Checkpointing vs. Migration for Post-Petascale Supercomputers
An alternative to classical fault-tolerant approaches for large-scale clusters is failure avoidance, by which the occurrence of a fault is predicted and a preventive measure is taken. We develop analytical performance models for two types of preventive measures: preventive checkpointing and preventive migration. We also develop an analytical model of the performance of a standard periodic checkpoint fault-tolerant approach. We instantiate these models for platform scenarios representative of current and future technology trends. We find that preventive migration is the better approach in the short term by orders of magnitude. However, in the longer term, both approaches have comparable merit with a marginal advantage for preventive checkpointing. We also find that standard non-prediction-based fault tolerance achieves poor scaling when compared to prediction-based failure avoidance, thereby demonstrating the importance of failure prediction capabilities. Finally, our results show that achieving good utilization in truly large-scale machines (e.g., $2^{20}$ nodes) for parallel workloads will require more than the failure avoidance techniques evaluated in this work.
Joel Saltz, Emory U
Towards Derivation, Management and Analysis of Exascale Feature Sets
Integrative analysis of large scale temporal spatial datasets is playing an increasingly important role in many areas of science and engineering. We outline middleware infrastructure requirements to extract, manage and analyze broadly descriptive, reproducible and semantically meaningful information from very large image, sensor or simulation datasets. This is both a compute and data intensive problem. The need for descriptiveness motivates the need to run complementary multi-scale analysis algorithms while the need for reproducibility drives the need to run many different algorithms aimed at extracting the same information. The analyses derive many very large semantically complex feature sets that must be repeatedly managed, queried and re-analyzed.
This talk will describe both motivating application scenarios involving complementary digital microscopy, Radiology and “omic” analyses in cancer research and will describe the systems software effort being launched to address the challenges posed by this kind of integrative analysis.
Martin Swany, U of Delaware
Shining a light on the I/O problem
This talk will describe the Photon system, which aims to help address the I/O problem in extreme scale HPC environments. Photon builds on our previous work in MPI optimization and wide-area data movement to construct a pipeline of data between parallel applications and distributed storage.
Rajeev Thakur, Argonne National Laboratory
Future Directions in MPI
This talk will discuss issues that need to be addressed in the MPI standard as well as in MPI implementations to enable MPI to scale well to exascale. I will present some cases where we already encountered (and fixed) some of these issues on Argonne's leadership-class IBM Blue Gene/P. I will also give an update on recent activities of the MPI Forum and what features are being considered for inclusion in MPI-3.
Rich Vuduc, GATech
Should I port my code to a GPU?
In this talk, I make the perhaps provocative and surprising claim that a GPU is no more powerful than a CPU, even in cases where one might have expected a GPU to win big.
In particular, I summarize our recent experience in analyzing and tuning both multithreaded CPU and GPU implementations of three computations in scientific computing. These computations—(a) iterative sparse linear solvers; (b) sparse Cholesky factorization; and (c) the fast multipole method—exhibit complex behavior and vary in computational intensity and memory reference irregularity. In each case, algorithmic analysis and prior work might lead us to conclude that an idealized GPU can deliver significantly better performance, but we find that for at least equal-effort CPU tuning and consideration of realistic workloads and calling-contexts, we can with two modern quad-core CPU sockets roughly match one or two GPUs in performance.
These conclusions are not intended to dampen interest in GPU acceleration; on the contrary, they should do the opposite: they partially illuminate the boundary between CPU and GPU performance, and ask architects to consider application contexts in the design of future coupled on-die CPU/GPU processors.
David W. Walker, Cardiff University, U. K.
Automatic Generation of Portals for Distributed Scientific Applications
This talk considers issues in the generation of portal interfaces for executing scientific applications on distributed resources, in particular the extent to which the automatic generation of such interfaces is possible and desirable. In general, an application portal provides a user-friendly problem-solving environment that addresses job assignment, job submission and job feedback, whilst hiding from the user the complexity of handling these tasks in the distributed environment. However, the manual development and configuration of the application portal often requires considerable expertise in web portal techniques, which most scientific end-users do not have. This main part of this talk addresses this problem by means of a prototype software system that allows an end-user to build automatically a customized portal for managing and executing distributed scientific and engineering computations in a service-oriented environment, based on an XML description of the application workflow. In addition to describing this prototype system the talk also outlines recent work on embedding interfaces to remote computational resources in scientific publications.
Michael Wolfe, PGI
Explicit vs. Implicit Programming: Language, Directive, Library
We explore the landscape of parallel programming methods, and the features (good and bad) of each. We use three scenarios. (1) Distributed memory programming using HPF, MPI and CAF. (2) Shared memory multiprocessor or multicore programming using POSIX threads, OpenMP and various parallel languages. (3) GPU programming using CUDA or OpenCL and the PGI Accelerator model.
Xingfu Wu, Texas A&M
Energy and Performance Characteristics of MPI, OpenMP and Hybrid Scientific Applications on Multicore Systems
Energy is a major concern with high performance multicore systems. This talk will focus on the energy and performance characteristics for MPI, OpenMP, and MPI/OpenMP scientific applications. We use the power profiling tool, PowerPack (developed at Virginia Tech), to obtain power profiling data, and Prophesy to collect the execution time data. The work is focused on three scientific applications -- a NAS parallel BT benchmark (strong scaling), a Gyrokinetic Toroidal Code (GTC) (weak scaling), and a Lattice Boltzmann code (weak scaling). Our experimental results indicate that in most cases using the hybrid MPI/OpenMP implementation achieves better energy as compared to MPI-only implementation. For example, with the hybrid GTC versus the MPI GTC for 32 cores results in a 72% reduction in energy. This work is part of the NSF-funded MuMI (Multicore application Modeling Infrastructure) Project, which facilitates systematic measurement, modeling, and prediction of performance, power consumption and performance-power tradeoffs for multicore systems.
Hans P. Zima, Jet Propulsion Laboratory, California Institute of Technology and University of Vienna, Austria
Enhancing the Dependability of Extreme-Scale Applications
Emerging massively parallel extreme-scale systems will be providing the superior computational capability required for dramatic advances in fields such as DNA analysis, drug design, climate modelling, and astrophysics. These systems will be composed of devices less reliable than those used today, and faults will become the norm, not the exception. This will pose significant problems for users, who for half a century have enjoyed an execution model that largely relied on correct behavior by the underlying computing system. In this talk we outline an approach that will enhance the dependability of extreme-scale applications. Such applications and the systems they run on must be introspective and adaptive, actively searching for errors in their program state with hardware mechanisms and new software techniques. An introspection framework, which is built around an inference engine and an associated knowledge base, will monitor the execution of the system, analyze errors and subsystem failures, and provide feedback to both the application and the operating system. Domain knowledge will be leveraged in the form of user input, knowledge about applicable fault tolerance mechanisms, and compiler analysis as a way to reduce the need for recovery mechanisms. The result is a self-aware system that can deal with errors in a sophisticated way, ignoring them if possible, attempting corrections, or reverting to an earlier checkpoint when necessary.
Biographies of Attendees
Wes Alvaro
David Bader
David A. Bader is a Full Professor in the School of Computational Science and Engineering, College of Computing, at Georgia Institute of Technology. Dr. Bader has also served as Director of the Sony-Toshiba-IBM Center of Competence for the Cell Broadband Engine Processor. He received his Ph.D. in 1996 from The University of Maryland, was awarded a National Science Foundation (NSF) Postdoctoral Research Associateship in Experimental Computer Science. He is an NSF CAREER Award recipient, an investigator on several NSF and NIH awards, was a distinguished speaker in the IEEE Computer Society Distinguished Visitors Program, and a member of the IBM PERCS team for the DARPA High Productivity Computing Systems program. Dr. Bader serves on the Research Advisory Council for Internet2, the Steering Committees of the IPDPS and HiPC conferences, and is the General Chair of IPDPS 2010 and Chair of SIAM PP12. He is an associate editor for several high impact publications including the ACM Journal of Experimental Algorithmics (JEA), IEEE DSOnline, and Parallel Computing, has been an associate editor for the IEEE Transactions on Parallel and Distributed Systems (TPDS), is an IEEE Fellow and a Member of the ACM. Dr. Bader's interests are at the intersection of high-performance computing and computational biology and genomics. He has co-chaired a series of meetings, the IEEE International Workshop on High-Performance Computational Biology (HiCOMB), co-organized the NSF Workshop on Petascale Computing in the Biological Sciences, written several book chapters, and co-edited special issues of the Journal of Parallel and Distributed Computing (JPDC) and IEEE TPDS on high-performance computational biology. He has co-authored over 100 articles in peer-reviewed journals and conferences, and his main areas of research are in parallel algorithms, combinatorial optimization, and computational biology and genomics.
Rose M. Badia
Rosa M. Badia received the B.Sc. and Ph.D. degrees in computer science from the Technical University of Catalonia, Barcelona, Spain in 1989 and 1994. From 1989 to 2007 she has been lecturing at the Technical University of Catalonia on computer organization and architecture and VLSI design, both in undergraduate and graduate programmes.
She held an Associate Professor position at the Department of Computer Architecture, Technical University of Catalonia from 1997 till 2007.
Since May 2008 she is a Scientific Researcher at the Spanish National Research Council (CSIC). Since year 2005 she is the manager of Grid computing and clusters at the Barcelona Supercomputing Center, position that she currently holds at full-time. Her current research interests includes performance prediction and modelling of MPI applications, programming models for multi-core architectures and programming models for Grid environments. She has participated in several international research projects. She has more than 60 publications in international conferences and journals.
Pete Beckman
Division Director, Argonne Leadership Computing Facility
Pete Beckman is a recognized global expert in high-end computing systems. During the past 20 years, he has designed and built software and architectures for large-scale parallel and distributed computing systems. After receiving his Ph.D. degree in computer science from Indiana University, he helped found the university’s Extreme Computing Laboratory. In 1997 Pete joined the Advanced Computing Laboratory at Los Alamos National Laboratory.In 2000 he established a Turbolinux-sponsored research laboratory in Santa Fe that developed the world's first dynamic provisioning system for cloud computing and high performance computing (HPC) clusters. The following year, Pete became Vice President of Turbolinux's worldwide engineering efforts, managing development offices worldwide.
Pete joined Argonne National Laboratory in 2002 as Director of Engineering. Later, as Chief Architect for the TeraGrid, he designed and deployed the world's most powerful Grid computing system for linking production HPC computing centers. Pete then started a research team focusing on petascale high-performance software systems, wireless sensor networks, Linux, and the SPRUCE system to provide urgent computing for critical, time-sensitive decision support.
In 2008 he became Director of the Argonne Leadership Computing Facility, home to one of the world's fastest open science supercomputers. He also leads Argonne's exascale computing strategic initiative.
Anne Benoit
Anne Benoit is an ENSIMAG engineer (Applied Mathematics and Computer Science). She obtained her PhD in 2003 at the Polytechnical Institute of Grenoble (INPG). From 2003 to 2005, she was a Research Associate at the University of Edinburgh, UK. She currently holds a position of Assistant Professor at Ecole Normale Supérieure in Lyon, France. Her research interests include parallel and distributed computing, with an emphasis on algorithms, scheduling and high-level parallel programming (algorithmic skeletons), on distributed heterogeneous platforms (clusters and grids). Anne Benoit is the author of 17 international journal papers and 48 international conference papers. She passed the French HDR (Habilitation a Diriger des Recherches) in 2009, entitled "Scheduling pipelined applications: models, algorithms and complexity". She is a senior member of the IEEE. In 2009, she was elected as Junior Member of Institut Universitaire de France.
Nan Boden
Nanette (Nan) Boden is a founder of Myricom, Inc. and now serves as President & CEO. Over her sixteen years with Myricom, Nan has served in several sales and operations positions within the company, including Executive Vice President and CFO. Nan has been a member of the Myricom Board of Directors since 2001. She earned her B.S. degree in Applied Mathematics from the University of Alabama and her M.S. and Ph.D. degrees in Computer Science from the California Institute of Technology (Caltech).
George Bosilca
Dr. Bosilca is a Research Assistant Professor at the Innovative Computing Laboratory (ICL), University of Tennessee Knoxville. He received a Ph.D. degree in parallel architectures from the University Paris XI. His Ph.D was focused on parallel environments based on automatic data dependencies graphs, and fault tolerance. His research topics include high performance networks, collective communication libraries, fault tolerance, high performance algorithms and message passing paradigms. He was one of the main developers for MPICH-V and FT-MPI. Today, Dr. Bosilca is an active participant in several open source projects such as STCI, AtomS and Open MPI.
Aurelien Bouteiller
Aurelien Bouteiller is a senior research associate in the Innovative Computing Laboratory of the department of Computer Science and Electrical Engineering at University of Tennessee Knoxville. He received is Ph.D in computer science from University of Paris in 2007, under the direction of Franck Cappello. His current research interests includes parallel and distributed computing, fault tolerant frameworks, scalable run-time environments and high performance message passing interfaces.
Bill Brantley
Advanced Micro Devices, Austin, TX
Bill received his Ph.D. in Computer Engineering from Carnegie-Mellon University in 1978 and then joined the IBM T. J. Watson Research Center where he began adding vector instructions to the 370 architecture.
Next, he led the team that designed the processing element and switch for the DARPA sponsored RP3 project and then began studying its performance using custom hardware instrumentation. In 1990 he moved to IBM in Austin, TX joining the Risc System 6000 performance team and finally the Linux Technology Center before joining Advanced Micro Devices in 2002 where he is a Principal Member of Technical Staff and the leader of AMD's HPC performance team. Bill has been contributing to the SPEC organization since 1995 and is currently a member of the SPEC High Performance Group which developed the SPEC MIP2007 benchmark.
Kirk Cameron
Kirk W. Cameron received his B.S. in Mathematics from the University of Florida (2004) and Ph.D. in Computer Science from Louisianan State University (2000). From 1998-2000 he was a Computer Science researcher at Los Alamos National Laboratory. From 2001-2005 he was an assistant professor of Computer Science and Engineering at the University of South Carolina. In 2005, he joined Virginia Tech as an associate professor of Computer Science. He is Director of the Scalable Performance (SCAPE) Laboratory at Virginia Tech where he leads research to improve the efficiency of high-performance systems. Prof. Cameron pioneered the area of high-performance, power-aware computing. He participated in the development of SPECPower, the first commercial benchmark for energy efficiency and consults regularly with the US EPA in its attempt to establish Energy Star ratings for computer servers. He also co-founded the Green500, a list of the most energy efficient supercomputers in the world. Prof. Cameron is a recipient of NSF Career, DOE Career, and IBM Faculty Awards. In 2007, he was named a research fellow in the Virginia Tech College of Engineering. In 2008, he was invited to participate in the US National Academy of Engineering Frontiers of Engineering Syposium, an invitation-only congregation of the best and brightest young engineers in the United States.
Franck Cappello
Franck Cappello holds a Senior Researcher position at INRIA. He leads the Grand-Large project at INRIA, focusing on High Performance issues in Large Scale Distributed Systems. He has initiated the XtremWeb (Desktop Grid) and MPICH-V (Fault tolerant MPI) projects. He was the director of the Grid5000 project, a nationwide computer science platform for research in large scale distributed systems. He is the scientific director of ALADDIN/Grid5000, the new 4 years INRIA project aiming to sustain the Grid5000 infrastructure and to open it to researches in Cloud Computing, Service Infrastructures and the Future Internet. He has authored papers in the domains of High Performance Programming, Desktop Grids, Grids and Fault tolerant MPI. He has contributed to more than 50 Program Committees. He is editorial board member of the international Journal on Grid Computing, Journal of Grid and Utility Computing and Journal of Cluster Computing. He is a steering committee member of IEEE HPDC and IEEE/ACM CCGRID. He is the General co-Chair of IEEE APSCC 2008, Workshop co-chair for IEEE CCGRID'2008, Program co-Chair of IEEE CCGRID'2009 and was the General Chair of IEEE HPDC'2006.
Anthony Danalis
Ewa Deelman
Ewa Deelman is an Assistant Research Professor at the USC Computer Science Department and a Project Leader at the USC Information Sciences Institute. Dr. Deelman's research interests include the design and exploration of collaborative, distributed scientific environments, with particular emphasis on workflow management as well as the management of large amounts of data and metadata. At ISI, Dr. Deelman is leading the Pegasus project, which designs and implements workflow mapping techniques for large-scale workflows running in distributed environments. Dr. Deelman received her PhD from Rensselaer Polytechnic Institute in Computer Science in 1997 in the area of parallel discrete event simulation.
Jack Dongarra
Jack Dongarra holds an appointment as University Distinguished Professor of Computer Science in the Electrical Engineering and Computer Science Department at the University of Tennessee and holds the title of Distinguished Research Staff in the Computer Science and Mathematics Division at Oak Ridge National Laboratory (ORNL), Turing Fellow in the Computer Science and Mathematics Schools at the University of Manchester, and an Adjunct Professor in the Computer Science Department at Rice University. He specializes in numerical algorithms in linear algebra, parallel computing, the use of advanced-computer architectures, programming methodology, and tools for parallel computers. His research includes the development, testing and documentation of high quality mathematical software. He has contributed to the design and implementation of the following open source software packages and systems: EISPACK, LINPACK, the BLAS, LAPACK, ScaLAPACK, Netlib, PVM, MPI, NetSolve, Top500, ATLAS, and PAPI. He has published approximately 200 articles, papers, reports and technical memoranda and he is coauthor of several books. He was awarded the IEEE Sid Fernbach Award in 2004 for his contributions in the application of high performance computers using innovative approaches and in 2008 he was the recipient of the first IEEE Medal of Excellence in Scalable Computing; in 2010 he was the first recipient of the SIAM Special Interest Group on Supercomputing's award for Career Achievement. He is a Fellow of the AAAS, ACM, IEEE, and SIAM and a member of the National Academy of Engineering.
Peng Du
Peng Du is a Phd student at ICL working on fault tolerance and GPU related projects.
Geoffrey Fox
gcf@indiana.edu, http://www.infomall.org
Fox received a Ph.D. in Theoretical Physics from Cambridge University and is now professor of Computer Science, Informatics, and Physics at Indiana University where he is director of the Community Grids Laboratory and chair of the Informatics department. He is chief technology officer for Anabas Inc. He previously held positions at Caltech, Syracuse University and Florida State University. He has supervised the PhD of 58 students and published over 600 papers in physics and computer science. He currently works in applying computer science to Defense, particle physics, Earthquake and Ice-sheet Science and Chemical Informatics. Web 2.0, Grids(clouds) and multicore systems are his current interest. He is involved in several projects to enhance the capabilities of Minority Serving Institutions.
Al Geist
Oak Ridge National Lab
PO Box 2008
Oak Ridge, TN, 38731-6367
Al Geist is a Corporate Research Fellow at Oak Ridge National Laboratory. He is the Chief Technology Officer of the Leadership Computing Facility and also leads a 35 member Computer Science Research Group.
He is one of the original developers of PVM (Parallel Virtual Machine), which became a world-wide de facto standard for heterogeneous distributed computing. Al was actively involved in the design of the Message Passing Interface (MPI-1 and MPI-2) standard and is on the MPI-3 steering committee. His present research involves developing numerical algorithms for many-core processors and developing fault tolerant and self-healing algorithms for system software.
In his 22 years at ORNL, he has published two books and over 200 papers in areas ranging from heterogeneous distributed computing, numerical linear algebra, parallel computing, collaboration technologies, solar energy, materials science, biology, and solid state physics.
Al has won numerous awards in high-performance and distributed computing including: the Gordon Bell Prize (1990), the international IBM Excellence in Supercomputing Award (1990), an R&D 100 Award (1994), two DOE Energy 100 awards (2001), the American Museum of Science and Energy Award (1997), and the Supercomputing Heterogeneous Computing Challenge several times (1992, 1993, 1995, 1996).
You can find out more about Al and a complete list of his publications on his web page: http://www.csm.ornl.gov/~geist
Patrick Geoffray
Patrick Geoffray was born in France, but he is not French anymore. He received his PhD in 2000 from the University of Lyon, under the guidance of Bernard Tourancheau, and immediately joined Myricom. He has ported a few MPI implementations, designed the MX firmware, accelerated UDP sockets, developed adaptive routing techniques, and a few other things.
He also believes Grid computing people comes from the planet Melmac.
Bill Gropp
William Gropp is the Paul and Cynthia Saylor Professor in the Department of Computer Science and Deputy Director for Research for the Institute of Advanced Computing Applications and Technologies at the University of Illinois in Urbana-Champaign. He received his Ph.D. in Computer Science from Stanford University in 1982 and worked at Yale University and Argonne National Laboratory. His research interests are in parallel computing, software for scientific computing, and numerical methods for partial differential equations. He is a Fellow of ACM and IEEE and a member of the National Academy of Engineering.
Thomas Herault
Tony Hey
Microsoft Corp.
Corporate Vice President for Technical Computing
As corporate vice president for technical computing, Tony Hey coordinates efforts across Microsoft Corp. to collaborate with the global scientific community. He is a well-known researcher in the field of parallel computing, and his experience in applying computing technologies to scientific research helps Microsoft work with researchers worldwide in various fields of science and engineering.
Before joining Microsoft, Hey worked as head of the School of Electronics and Computer Science at the University of Southampton, where he helped build the department into one of the top five computer science research institutions in England. Since 2001, Hey has served as director of the United Kingdom’s e-Science Initiative, managing the government’s efforts to provide scientists and researchers with access to key computing technologies.
Hey is a fellow of the U.K.’s Royal Academy of Engineering and has been a member of the European Union’s Information Society Technology Advisory Group. He also has served on several national committees in the U.K., including committees of the U.K. Department of Trade and Industry and the Office of Science and Technology. Hey received the award of Commander of the Order of the British Empire honor for services to science in the 2005 U.K. New Year’s Honours List.
Hey is a graduate of Oxford University, with both an undergraduate degree in physics and a doctorate in theoretical physics.
Jeff Hollingsworth
Jeffrey K. Hollingsworth is a Professor and Associate Chair of the Computer Science Department at the University of Maryland, College Park. He also has an appointment in the University of Maryland Institute for Advanced Computer Studies and the Electrical and Computer Engineering Department. He received his PhD and MS degrees in computer sciences from the University of Wisconsin. He received a B. S. in Electrical Engineering from the University of California at Berkeley.
Dr. Hollingsworth’s research seeks to develop a unified framework to understand the performance of large systems and focuses in several areas. First, he developed new approach, called dynamic instrumentation, to permit the efficient measurement of large parallel applications. Second, he has developed an auto-tuning framework called Active Harmony that can be used to tune kernels, libraries, or full applications. Third, he is investigating the interactions between different layers of software and hardware to understand how they influence performance.
Heike Jagode
Heike Jagode received her B.Sc. and M.Sc. degrees in Applied Mathematics from The University of Applied Sciences, Mittweida, Germany in 2001. She earned her second M.Sc. in High Performance Computing from The University of Edinburgh, Edinburgh Parallel Computing Centre (EPCC) in Scotland in 2006. She held a Research Associate position at the Center for Information Services and High Performance Computing (ZIH) at The Dresden University of Technology in Germany from 2002 to 2008. Since March 2008 she is a Senior Research Associate at the Innovative Computing Laboratory (ICL) at The University of Tennessee in Knoxville (UTK). Heike's current research interests include studies in computer science for performance of high performance computing applications and architectures, focusing primarily on developing methods and tools for scalable performance analysis, tuning and optimization of HPC applications. She is also currently enrolled in a Ph.D. program at the Department of Computer Science at UTK (Fall 2009).
Emmanuel Jeannot
Emmanuel Jeannot is currently full-time researcher at INRIA (Institut National de Recherche en Informatique et en Automatique) and is doing its research at the LORIA laboratory, near Nancy France. From Sept. 1999 to Sept. 2005 he was associate professor at the Université Henry Poincaré, Nancy 1.
He got his PhD and Master degree of computer science (resp. in 1996 and 1999) both from Ecole Normale supérieure de Lyon.
His main research interests are scheduling for heterogeneous and large- scale environments, data redistribution, experimental tools, adaptive online compression and programming models.
Tahar Kechadi
Tahar Kechadi was awarded PhD and a DEA (Diplome d'Etude Approfondie) - Masters degree - in Computer Science from University of Lille 1, France. After working as a post-doctoral researcher under TMR program at UCD, he joined UCD in 1999 as a permanent staff member of the School of Computer Science & Informatics. He is currently Professor at School of Computer Science and Informatics, UCD.
His current research interests are primary in: 1) Grid and Cloud computing and Grid software, and 2) Distributed data mining on Grid and Cloud platforms. His current research projects’ goals are twofold: 1) design, develop and implement innovative distributed data mining techniques for real-world data intensive applications, such as telecommunication systems, banking and finance. 2) Provide these techniques with services and middleware tools in order to take advantage of the available distributed platforms such as the Grid and Cloud.
He is a member of the communication of the ACM journal and IEEE computer society.
Thilo Kielmann
Vrije Universiteit
Dept. of Computer Science
De Boelelaan 1083
1081HV Amsterdam
The Netherlands
Thilo Kielmann studied Computer Science at Darmstadt University of Technology, Germany. He received his Ph.D. in Computer Engineering in 1997, and his habilitation in Computer Science in 2001, both from Siegen University, Germany. Since 1998, he is working at Vrije Universiteit Amsterdam, The Netherlands, where he is currently Associate Professor at the Computer Science Department. His research interests are in the area of high-performance, distributed computing, namely programming environments and runtime systems for grid and cloud applications. He is a steering group member of the Open Grid Forum and of Gridforum Nederland.
Jakub Kurzak
Alexey Lastovetsky
Alexey Lastovetsky received a PhD degree from the Moscow Aviation Institute in 1986, and a Doctor of Science degree from the Russian Academy of Sciences in 1997. His main research interests include algorithms, models and programming tools for high performance heterogeneous computing. He is the author of mpC, the first parallel programming language for heterogeneous networks of computers. He designed HeteroMPI, an extension of MPI for heterogeneous parallel computing (with R. Reddy), and SmartGridSolve, an extension of GridSolve aimed at higher performance of scientific computing on global networks (with T. Brady, et al.). He has contributed into heterogeneous data distribution algorithms (with A. Kalinov, R. Reddy, et al.), proposed and studied realistic performance models of processors in heterogeneous environments, including the functional model and the band model (with R. Reddy and R. Higgins). He also works on analytical communication performance models for homogeneous and heterogeneous clusters. He published over 90 technical papers in refereed journals, edited books and proceedings of international conferences. He authored the monographs "Parallel computing on heterogeneous networks" (Wiley, 2003) and "High performance heterogeneous computing" (with J. Dongarra; Wiley, 2009). He is currently a senior lecturer in the School of Computer Science and Informatics at University College Dublin, National University of Ireland. At UCD, he is also the founding Director of the Heterogeneous Computing Laboratory (http://hcl.ucd.ie/).
Laurent Lefevre
Laurent Lefèvre obtained his Ph.D. in Computer Science in January 1997 at LIP Laboratory (Laboratoire Informatique du Parallelisme) in ENS-Lyon (Ecole Normale Supérieure), France. From 1997 to 2001, he was assistant professor in computer science in Lyon 1 University and a member of the RESAM Laboratory (High Performance Networks and Multimedia Application Support
Lab.) Since 2001, he is a permanent researcher in computer science at INRIA (the French Institute for Research in Computer Science and Control). He is a member of the RESO team (High Performance Networks, Protocols and Services) from the LIP laboratory in Lyon, France. He has organized several conferences in high performance networking and computing and he is a member of several program committees.
He has co-authored more than 60 papers published in refereed journals and conference proceedings. He is a member of IEEE and takes part in several research projects. His research interests include: grid and distributed computing and networking, power aware systems, autonomic networking, fault tolerance, high performance networks protocols and services, autonomic and active networks and services, active grid, disruption-tolerant networking, cluster computing, distributed shared memory systems and data consistency. His web site is: http://perso.ens-lyon.fr/laurent.lefevre
Andrew Lumsdaine
Andrew Lumsdaine received the PhD degree in Electrical Engineering and Computer Science from the Massachusetts Institute of Technology in 1992. He is presently a Professor of Computer Science at Indiana University, where he is also the director of the Open Systems Laboratory. His research interests include computational science and engineering, parallel and distributed computing, mathematical software, numerical analysis, and radiance photography.
Piotr Luszczek
Piotr Luszczek has recently rejoined ICL at the University of Tennessee Knoxville as a Research Scientist. Before that he worked on parallel MATLAB at the MathWorks. He earned his doctorate degree for the innovative use of dense matrix computational kernels in sparse direct and iterative numerical linear algebra algorithms.
He applied this experience to develop fault-tolerant libraries that used out-of-core techniques. His current work involves standardization of benchmarking of large supercomputer installations. He is an author of self-adapting software libraries that automatically choose the best algorithm to efficiently utilize available hardware and can optimally process the input data. He is also involved in high performance programming language design and implementation.
Satoshi Matsuoka
Satoshi Matsuoka is a full Professor at the Global Scientific Information and Computing Center (GSIC) of Tokyo Institute of Technology (Tokyo Tech). He is the technical leader in the construction of the TSUBAME supercomputer, which became the fastest supercomputer in Asia-Pacific in June, 2006, and continued to be Japan's #1 for 4 consecutive Top 500s during June 2006 - May 2008. He has also pioneered Grid computing research in Japan, and in particular co-lead the Japanese $100 million NAREGI project, whose aim was to develop and foster research grid infrastructure in Japan. He has chaired many ACM/IEEE international conferences, and will be the technical papers chair for SC09. He has won many awards including the JSPS Prize from the Japan Society for Promotion of Science in 2006, from his Majesty Prince Akishinomiya, for the first time as a Computer Scientist.
Shirley Moore
Terry Moore
Terry Moore is currently Associate
Director of the Innovative Computing Laboratory at the Computer Science
Department at University of Tennessee. He received his BA in Philosophy from
Purdue University and his Ph.D. in Philosophy from the University of North
Carolina, Chapel Hill. His research interests include collaboration
technologies, distributed and grid computing, long term digital preservation
and logistical networking.
Christine Morin
Christine Morin received her engineering degree from the Institut National des Sciences Appliquées (INSA), of Rennes (France), in 1987 and master and PhD degrees in Computer Science from the University of Rennes I in 1987 and 1990, respectively. In March 1998, She got her Habilitation à Diriger des Recherches in Computer Science from the Université de Rennes 1.
Since 1991, she has held a researcher position at INRIA and has carried out her research activities at IRISA/INRIA-Rennes. Since January 2000, she has been a member of the INRIA PARIS project-team contributing to the programming of large scale parallel and distributed systems. From October 2000 to August 2002, she has held a temporary assistant professor position at IFSIC (University of Rennes I). Since September 2002, she has held a senior researcher position at INRIA. Since January 2010, she is the head of the new Myriads research team on the design and implementation of autonomous distributed systems.
She led research activities on single system image OS for high performance computing in clusters, resulting in Kerrighed cluster OS, now developed in open source (http://www.kerrighed.org). She is a co-founder of Kerlabs start-up, created in 2006 to exploit Kerrighed technology (http://www.kerlabs.com). She is the scientific coordinator of the XtreemOS project which is a 4-year European integrated project started in June 2006 (http://wwwxtreemos.eu). Her research interests are in operating systems, distributed systems, fault tolerance, cluster, grid and cloud computing. She is the author of more than 100 papers in referred international journals and conferences. She is a member of ACM and IEEE.
Christian Obrecht
Phil Papadopoulos
Dr.
Papadopoulos received his PhD in 1993 from UC Santa Barbara in Electrical
Engineering. He spent 5 years at Oak Ridge National Laboratory as part of the
Parallel Virtual Machine (PVM) development team. He came to UCSD as research
professor in computer science in 1998 and still holds and adjunct
appointment. He is currently the Director for UC Systems at the San Diego
Supercomputer Center (SDSC). UC systems focuses on providing robust
computing and storage infrastructure for University of California researchers
and their colleagues. He is the architect of the Triton resource (tritonresource.sdsc.edu)
which is a network, storage and memory rich, mid-scale (3000 core) cluster that
is also an ongoing experiment in economic sustainability for campus-scale
computing. In addition to duties at SDSC, his research interests revolve
around distributed, clustered, and cloud-based systems and how they can be used
more effectively in an expanding bandwidth-rich environment. Dr.
Papadopoulos is a deeply involved investigator for key research projects at
UCSD including The National Biomedical Computation Resource (NBCR), the Pacific
Rim Applications and Grid Middlware Assembly (PRAGMA) and the Community
Cyberinfrastructure for Advanced Marine Microbial Ecology Research and Analysis
(CAMERA). He is well known for leading the development of the open-source,
NSF-funded Rocks Cluster toolkit (OCI-0721623), which has installed base of
1000s of clusters. Rocks (www.rocksclusters.org)
is used for both research and production systems with scalability to 1000s of
nodes. Our work in Rocks focuses on developing practical, scalable,
and robust virtual machine authoring and implementation of hybrid clusters
that consist of both real and virtual hardware. More recently, we have
demonstrated seamlessly extending the number of nodes in a local cluster with
additional virtualized resources housed on campus clouds and/or in Amazon
EC2.
Manish Parashar
Jelena Pjesivac-grbovic
Google Inc.
1600 Amphitheatre Pkwy
Mountain View, CA 94043
Jelena Pjesivac-Grbovic is an Software Engineer in Systems Infrastructure at Google Inc. She received PhD in Computer Science from the University of Tennessee, Knoxville focused on automatic and adaptive optimizations of MPI collective operations under supervision of Dr. Jack Dongarra, Dr. George Bosilca, and Dr. Graham Fagg. At the University of Tennessee, she was an active developer on FT-MPI and OpenMPI projects. Prior to the UT, she worked as an undergraduate research assistant at the Mathematical Modeling and Analysis group at the Los Alamos National Laboratory, modeling tumor growth under supervision of Dr. Ji Yiang. She received B.S. degrees in Computer Science and Physics from Ramapo College of New Jersey.
Jim Plank
Professor
Department of Electrical Engineering and Computer Science University of Tennessee
203 Claxton Complex
1122 Volunteer Blvd.
Knoxville, TN 37996-3450
865-974-4397
James S. Plank received his B.S. from Yale University in 1988 and his Ph.D. from Princeton University in 1993. He is a Professor in the Electical Engineering and Computer Science department at the University of Tennessee. His research interests are in fault-tolerance, storage systems, erasure coding and distributed computing. His current focus is the design and implementation of high performance erasure codes to tolerate failures in storage systems, and he is the author of Jerasure, an open-source erasure-coding library that has seen wide-scale use in industry and academia. He is a past Associate Editor of IEEE Transactions on Parallel and Distributed Computing, and a member of the IEEE Computer Society.
Thierry Priol
Thierry Priol is senior scientist at INRIA. He got a PhD in computer science from the University of Rennes 1 in 1989 and a “Habilitation à diriger des recherches” in 1995. He carried out research actitivies in the area of parallel computing, parallel rendering and software tools based on the shared virtual memory concept. He was involved in research activities dealing with the programming of grid infrastructures in particular the design of software components for code coupling applications. More recently, he launched a research activity aiming at programming service infrastructres using the chemical computing paradigm. He is one of the co-founder and scientific advisor of the Kerlabs spin-off started in 2006 and selling operating system technologies for PC clusters.
From 1999 till 2009, he was the scientific leader of the PARIS project-team at INRIA Rennes Bretagne Atlantique. From 2000 till 2003, he was the deputy chair of the INRIA evaluation committee. From 2003 till 2007, he was the head of the ACI GRID from the Ministry of Research, the national grid initiative. From 2004 till 2008, he acted as the scientific coordinator of the CoreGRID network of excellence funded by the European Commission.
From April 2009, he is Deputy Scientific Director assigned to the Research Department and the European Partnership Department in charge of the Networks, Systems and Services, Distributed Computing domain.
Irene Qualters
Padma Raghavan
Raghavan joined Penn State in Fall 2000 as a tenured Associate Professor in the Department of Computer Science and Engineering. She was subsequently promoted to Professor of Computer Science and Engineering in May 2005. In July 2007, Raghavan was appointed the first Director of the Institute for CyberScience at Penn State to promote multidisciplinary research and education in discovery and design through computation, mathematical modeling and data analysis.
Raghavan's research concerns high-performance computing and computational science. Focus areas include: algorithms for scalable sparse graph (symbolic) and matrix (numeric) computations including partitioning, mining and fast solvers, energy-aware performance scaling in chip multicore multiprocessor petascale regimes, and systems for multiscale modeling, simulation and knowledge extraction with a focus on scalable parallel algorithms, energy-aware supercomputing and large-scale modeling and simulation.
Yves Robert
Yves Robert received the PhD degree from Institut National Polytechnique de Grenoble in 1986. He is currently a full professor in the Computer Science Laboratory LIP at ENS Lyon. He is the author of five books, 100+ papers published in international journals, and
130+ papers published in international conferences. His main research
interests are scheduling techniques and parallel algorithms for clusters and grids. Yves Robert served on many editorial boards, including IEEE TPDS. He was the program chair of HiPC'2006 in Bangalore and of IPDPS'2008 in Miami. He is a Fellow of the IEEE.
He has been elected a Senior Member of Institut Universitaire de France in 2007.
Joel Saltz
Prior to coming to Emory, Dr. Joel H. Saltz was Dorothy M. Davis Professor in Cancer Research and Chair of the Department of Biomedical Informatics, Professor in the Department of Computer Science and Engineering, Professor and Vice Chair and Director of Pathology Informatics in the Department of Pathology, and Associate Vice President for Health Sciences at The Ohio State University. He also was Professor of Pathology and Informatics in the Department of Pathology at Johns Hopkins Medical School and Professor in the Department of Computer Science at the University of Maryland. Dr. Saltz is trained both as a computer scientist and as a medical scientist. He received BS and MS degrees in Mathematics and Physics from the University of Michigan and his MD-PhD in Computer Science from Duke University. He completed his residency in Clinical Pathology at Johns Hopkins University with extensive training in microbiology under Dr. William Merz and Dr. James Dick, and is a board certified Clinical Pathologist.
Jennifer Schopf
Dr. Jennifer M. Schopf is a program officer at the National Science Foundation, originally in the Office of CyberInfrastructure where she specialized in middleware, networking, and campus bridging programs with an emphasis on sustainable approaches to pragmatic software infrastructure and currently in EPSCoR. She also holds an appointment at the Woods Hole Oceanographic Institution (WHOI), where she is helping to develop a vision and implementation strategy to strengthen WHOI’s participation in cyberinfrastructure and ocean informatics programs. Prior to this, she was a Scientist at the Distributed Systems Lab at Argonne National Laboratory for 7 years, and spent 3½ years as a researcher at the National eScience Center in Edinburgh, UK. She received MS and PhD degrees from the University of California, San Diego in Computer Science and Engineering and a BA from Vassar College. Currently, her research interests include monitoring, performance prediction, and anomaly detection in distributed system environments. She has co-edited a book, co-authored over 50 refereed papers, and given over 100 invited talks.
Satoshi Sekiguchi
He was born in 1959, received B.S. from Department of Information Science, Faculty of Science, the University of Tokyo in 1982, and M.SE. from University of Tsukuba in 1984 respectively. He joined Electrotechnical Laboratory, Agency of Industrial Science and Technology in 1984 to engage research in high performance and parallel computing widely from the computer architecture, compiler, numerical algorithm, performance evaluation methods. He served as the deputy director of Research Institute of Information Technology, AIST in 2001, had been the founding director of Grid Technology Research Center (GTRC), AIST in 2002-2008. He is currently the Director of Information Technology Research Institute (ITRI), AIST. Presently, The research led by himself and/or his team is being undertaken on advanced grid programming tools such as Ninf/GridRPC and GridMPI, high-speed networking, the demonstration of applications using grid technology (including earth science), and on issues that are crucial to the actual deployment of grid technology for data centers. He has been contributing to the Open Grid Forum as a member of board of directors, and is also a member of IEEE, SIAM, IPSJ.
Fengguang Song
Fengguang Song is a Postdoc Research Associate in ICL where he works on the PLASMA and MAGMA projects. He earned his PhD in Computer Science from the University of Tennessee at Knoxville in 2009. His research interests are in high performance computing, multicore/GPGPU and multithreaded architectures, and automatic performance analysis.
Martin Swany
Martin Swany is an Associate Professor in the Department of Computer and Information Sciences at the University of Delaware. He received his B.A. and M.S. from the University of Tennessee in 1992 and 1998, respectively. He completed his Ph.D. at the University of California, Santa Barbara in 2003 and joined the faculty of the University of Delaware that year. He is a 2004 recipient of the US Department of Energy Early Career Principal Investigator award. Since 2005, Swany has been the Internet2 Faculty Fellow involving work in network metrics and performance-enhancing middleware. His research interests include high-performance parallel and distributed computing and networking.
Thomas Sterling
Dr. Thomas Sterling is a Professor of Computer Science at Louisiana State University, a Faculty Associate at California Institute of Technology, a Distinguished Visiting Scientist at Oak Ridge National Laboratory, and a Fellow of Computer Science Research Institute at Sandia National Laboratory. He received his PhD as a Hertz Fellow from MIT in 1984. Dr. Sterling is probably best known as the “father” of Beowulf clusters and for his research on Petaflops computing architecture. He was one of several researchers to receive the Gordon Bell Prize for this work on Beowulf 1997. In 1996, he started the inter-disciplinary HTMT project to conduct a detailed point design study of an innovative Petaflops architecture. He currently leads the MIND memory accelerator architecture project for scalable data-intensive computing and is an investigator on the DOE sponsored Fast-OS Project to develop a new generation of configurable light-weight parallel runtime software system. Thomas is co-author of five books and holds six patents.
Vaidy Sunderam
Vaidy Sunderam is a faculty member at Emory University. His research interests are in parallel and distributed processing systems and infrastructures for collaborative computing. His prior and current research efforts have focused on system architectures and implementations for heterogeneous metacomputing, including the Parallel Virtual Machine system and several other frameworks including IceT, CCF, Harness, and Unibus. Vaidy teaches computer science at the beginning, advanced, and graduate levels, and advises graduate theses in the area of computer systems.
Martin Swany
Martin Swany is an Assistant Professor in the Department of Computer and Information Sciences at the University of Delaware. He received his B.A. and M.S. from the University of Tennessee in 1992 and 1998, respectively. He completed his Ph.D. at the University of California, Santa Barbara in 2003 and joined the faculty of the University of Delaware that year. He is a 2004 recipient of the US Department of Energy Early Career Principal Investigator award. Since 2005, Swany has been the Internet2 Faculty Fellow involving work in network metrics and performance-enhancing middleware. His research interests include high-performance parallel and distributed computing and networking.
Rajeev Thakur
Rajeev Thakur is a Computer Scientist in the Mathematics and Computer Science Division at Argonne National Laboratory, where he has been working for the past 15 years in the areas of message passing libraries and parallel I/O. He is also a Senior Fellow in the Computation Institute at the University of Chicago and an Adjunct Associate Professor at Northwestern University. He is an author of the ROMIO MPI-IO library and the MPICH2 MPI implementation and is an active participant in the MPI Forum.
Bernard Tourancheau
Prof. Bernard Tourancheau on leave from University of Lyon - France
After his studies of applied mathematics and computer science Bernard Tourancheau got a PhD from Institut National Polytechnique of Grenoble. He then obtained a CNRS Researcher position at Ecole Normale Superieur de Lyon in 1989 and spent two years on leave at the University of Tennessee. In 1995, he got a Professor position at the University of Lyon where he created a research laboratory associated within INRIA, specialized in high speed networking and clusters. He joined SUN Microsystems Laboratories in 2000 as a Principal Investigator in the DARPA HPCS project. He is actually ending his sabbatical period, learning about research in renewable energy technologies.
Jeff Vetter
Jeffrey Vetter is a computer scientist in the Computer Science and Mathematics Division (CSM) of Oak Ridge National Laboratory (ORNL), where he leads the Future Technologies Group. His research interests lay largely in the areas of experimental software systems and architectures for high-end computing. Jeff earned his Ph.D. in Computer Science from the Georgia Institute of Technology; he joined CSM in 2003. Jeff is also an Adjunct Professor in the College of Computing at Georgia Tech.
Xavier Vigouroux
Rich Vuduc
Richard (Rich) Vuduc is an assistant professor in the School of Computational Science and Engineering at Georgia Tech. His research lab, The HPC Garage (hpcgarage.org), focuses on problems of performance analysis, tuning, and debugging. He received his PhD from the University of California, Berkeley and was a postdoc at Lawrence Livermore National Laboratory. He is a recipient of the NSF CAREER Award (2010), an R&D 100 Award (2009, joint with LLNL), and currently serves as a member of the 2009-2010 DARPA Computer Science Study Panel.
David Walker
David Walker is director of the Welsh e-Science Centre and a professor in the School of Computer Science of Cardiff University, where he heads the Distributed Collaborative Computing group. He has conducted research into parallel and distributed software environments for the past 20 years, about 10 years of which time was spent in the United States, and has published over 100 papers on these subjects. David played a leading role in initiating and guiding the development of the MPI specification for message-passing, and has co-authored a book on MPI. David also contributed to the ScaLAPACK library for parallel numerical linear algebra computations. David’s research interests include software environments for distributed scientific computing, problem-solving environments, parallel applications and algorithms, and cellular automata. David serves on the editorial boards of Concurrency and Computation: Practice and Experience, and The International Journal of High Performance Computing Applications.
Vince Weaver
Vince Weaver is a post-doc research associate at the Innovative Computing Lab at the University of Tennessee, Knoxville. His current research involves performance analysis involving PAPI and hardware performance counters. Other research interests include computer architecture, assembly language programming, embedded processors, and operating systems. He received his PhD in Electrical and Computer Engineering from Cornell University in 2010 and his BS in Electrical Engineering from the University of Maryland, College Park, in 2000.
Michael Wolfe
Michael Wolfe has worked on compilers for the high performance and parallel computing market in the commercial and academic world for over 30 years. He joined The Portland Group, Inc., as a compiler engineer in 1996; his responsibilities and interests include deep compiler analysis and optimization. He was an associate professor at the Oregon Graduate Institute from 1988 until 1996, and was a cofounder and lead compiler engineer at Kuck and Associates, Inc., prior to that. He has published one textbook, a monograph, and a number of technical papers.
Xingfu Wu
Xingfu Wu has been working at Texas A&M University as TEES Research Scientist since July 2003. He is a senior ACM member and an IEEE member. His research interests are performance evaluation and modeling, parallel and grid computing, and power and energy analysis in HPC systems. He served as session chairs and PC members for several international conferences, and was a guest editor of IEEE Distributed Systems Online Special Issue on Data-intensive Computing (Vol. 5, Issue 1, 2004). His monograph: Performance Evaluation, Prediction and Visualization of Parallel Systems was published by Kluwer Academic Publishers (ISBN 0-7923-8462-8) in 1999.
Hans Zima
Hans P. Zima is a Principal Scientist at JPL and a Professor Emeritus of the University of Vienna, Austria. He received his Ph.D. degree in Mathematics and Astronomy from the University of Vienna.
His major research interests have been in the fields of high-level programming languages, compilers, operating systems, and advanced software tools. In the early 1970s, while working in industry, he designed and implemented one of the first high-level real-time languages for the German Air Traffic Control Agency. During his tenure as a Professor of Computer Science at the University of Bonn, Germany, he contributed to the German supercomputer project “SUPRENUM”, leading the design of the first Fortran-based compilation system for distributed-memory architectures (1989). After his move to the University of Vienna, he became the chief designer of the Vienna Fortran language that provided a major input for the High Performance Fortran standard (1998). His research since joining JPL in 2001 included the design of the “Chapel” programming language in the framework of the DARPA-sponsored High Productivity Computing Systems (HPCS) program; more recently, he is leading an effort for providing software-based fault tolerance for future high-performance space-borne computing systems.
Dr. Zima is the author or co-author of about 200 publications, including 4 books.

CCGSC 1998 Participants, Blackberry Tennessee

CCGSC 2000 Participants, Faverges, France

CCGSC 2002 Participants, Faverges, France

CCGCS 2004 Participants, Faverges, France

CCGCS 2006 Participants, Flat Rock North Carolina
Some additional pictures from CCGSC 2006 can be found here.

CCGCS 2008 Participants, Flat Rock North Carolina

CCGCS 2010 Participants, Flat Rock North Carolina