Below are short descriptions of each of the methods to be discussed, along with brief notes on the classification of the methods in terms of the class of matrices for which they are most appropriate. In later sections of this chapter more detailed descriptions of these methods are given.
The Jacobi method is based on solving for every variable locally with respect to the other variables; one iteration of the method corresponds to solving for every variable once. The resulting method is easy to understand and implement, but convergence is slow.
The Gauss-Seidel method is like the Jacobi method, except that it uses updated values as soon as they are available. In general, if the Jacobi method converges, the Gauss-Seidel method will converge faster than the Jacobi method, though still relatively slowly.
Successive Overrelaxation (SOR) can be derived from the Gauss-Seidel
method by introducing an extrapolation parameter  . For the
optimal choice of , SOR may converge faster than Gauss-Seidel by
an order of magnitude.
. For the
optimal choice of , SOR may converge faster than Gauss-Seidel by
an order of magnitude.
Symmetric Successive Overrelaxation (SSOR) has no advantage over SOR as a stand-alone iterative method; however, it is useful as a preconditioner for nonstationary methods.
The conjugate gradient method derives its name from the fact that it generates a sequence of conjugate (or orthogonal) vectors. These vectors are the residuals of the iterates. They are also the gradients of a quadratic functional, the minimization of which is equivalent to solving the linear system. CG is an extremely effective method when the coefficient matrix is symmetric positive definite, since storage for only a limited number of vectors is required.
These methods are computational alternatives for CG for coefficient matrices that are symmetric but possibly indefinite. SYMMLQ will generate the same solution iterates as CG if the coefficient matrix is symmetric positive definite.
These methods are based on the application of the CG method to one of
two forms of the normal equations for
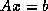 . CGNE solves the system
. CGNE solves the system 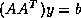 for
for 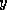 and then
computes the solution
and then
computes the solution 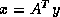 . CGNR solves
. CGNR solves 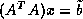 for the solution vector
for the solution vector  where
where 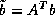 . When the
coefficient matrix
. When the
coefficient matrix 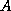 is nonsymmetric and nonsingular, the normal
equations matrices
is nonsymmetric and nonsingular, the normal
equations matrices 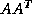 and
and 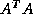 will be symmetric and positive
definite, and hence CG can be applied. The convergence may be slow,
since the spectrum of the normal equations matrices will be less
favorable than the spectrum of .
will be symmetric and positive
definite, and hence CG can be applied. The convergence may be slow,
since the spectrum of the normal equations matrices will be less
favorable than the spectrum of .
The Generalized Minimal Residual method computes a sequence of orthogonal vectors (like MINRES), and combines these through a least-squares solve and update. However, unlike MINRES (and CG) it requires storing the whole sequence, so that a large amount of storage is needed. For this reason, restarted versions of this method are used. In restarted versions, computation and storage costs are limited by specifying a fixed number of vectors to be generated. This method is useful for general nonsymmetric matrices.
The Biconjugate Gradient method generates two CG-like sequences of
vectors, one based on a system with the original coefficient
matrix , and one on 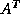 . Instead of orthogonalizing each
sequence, they are made mutually orthogonal, or
``bi-orthogonal''. This method, like CG, uses
limited storage. It is useful when the matrix is nonsymmetric and
nonsingular; however, convergence may be irregular, and there is a
possibility that the method will break down. BiCG requires a
multiplication with the coefficient matrix and with its transpose at
each iteration.
. Instead of orthogonalizing each
sequence, they are made mutually orthogonal, or
``bi-orthogonal''. This method, like CG, uses
limited storage. It is useful when the matrix is nonsymmetric and
nonsingular; however, convergence may be irregular, and there is a
possibility that the method will break down. BiCG requires a
multiplication with the coefficient matrix and with its transpose at
each iteration.
The Quasi-Minimal Residual method applies a least-squares solve and update to the BiCG residuals, thereby smoothing out the irregular convergence behavior of BiCG, which may lead to more reliable approximations. In full glory, it has a look ahead strategy built in that avoids the BiCG breakdown. Even without look ahead, QMR largely avoids the breakdown that can occur in BiCG. On the other hand, it does not effect a true minimization of either the error or the residual, and while it converges smoothly, it often does not improve on the BiCG in terms of the number of iteration steps.
The Conjugate Gradient Squared method is a variant of BiCG that
applies the updating operations for the -sequence and the
-sequences both to the same vectors. Ideally, this would double
the convergence rate, but in practice convergence may be much more
irregular than for BiCG,
which may sometimes lead to unreliable results. A practical
advantage is that the method does not need the multiplications with
the transpose of the coefficient matrix.
The Biconjugate Gradient Stabilized method is a variant of BiCG, like
CGS, but using different updates for the -sequence in order to
obtain smoother convergence than CGS.
The Chebyshev Iteration recursively determines polynomials with coefficients chosen to minimize the norm of the residual in a min-max sense. The coefficient matrix must be positive definite and knowledge of the extremal eigenvalues is required. This method has the advantage of requiring no inner products.