Portability of programs has always been an important consideration. Portability was easy to achieve when there was a single architectural paradigm (the serial von Neumann machine) and a single programming language for scientific programming (Fortran) embodying that common model of computation. Architectural and linguistic diversity have made portability much more difficult, but no less important, to attain. Users simply do not wish to invest significant amounts of time to create large-scale application codes for each new machine. Our answer is to develop portable software libraries that hide machine-specific details.
In order to be truly portable, parallel software libraries must be standardized. In a parallel computing environment in which the higher-level routines and/or abstractions are built upon lower-level computation and message-passing routines, the benefits of standardization are particularly apparent. Furthermore, the definition of computational and message-passing standards provides vendors with a clearly defined base set of routines that they can implement efficiently.
From the user's point of view, portability means that, as new machines are developed, they are simply added to the network, supplying cycles where they are most appropriate.
From the mathematical software developer's point of view, portability may require significant effort. Economy in development and maintenance of mathematical software demands that such development effort be leveraged over as many different computer systems as possible. Given the great diversity of parallel architectures, this type of portability is attainable to only a limited degree, but machine dependences can at least be isolated.
LAPACK is an example of a mathematical software package whose highest-level components are portable, while machine dependences are hidden in lower-level modules. Such a hierarchical approach is probably the closest one can come to software portability across diverse parallel architectures. And the BLAS that are used so heavily in LAPACK provide a portable, efficient, and flexible standard for applications programmers.
Like portability,
scalability demands that a
program be reasonably effective over a wide range of number of
processors.
The scalability of parallel algorithms, and software libraries based on
them, over a wide range of architectural designs and numbers of
processors will likely require that the fundamental granularity of
computation be adjustable to suit the particular circumstances in which
the software may happen to execute. Our approach to this
problem is block algorithms with adjustable block size.
In many cases, however, polyalgorithms![]() may be required to deal with the
full range of architectures and processor multiplicity likely to be
available in the future.
may be required to deal with the
full range of architectures and processor multiplicity likely to be
available in the future.
Scalable parallel architectures of the future are likely to be based on a distributed memory architectural paradigm. In the longer term, progress in hardware development, operating systems, languages, compilers, and communications may make it possible for users to view such distributed architectures (without significant loss of efficiency) as having a shared memory with a global address space. For the near term, however, the distributed nature of the underlying hardware will continue to be visible at the programming level; therefore, efficient procedures for explicit communication will continue to be necessary. Given this fact, standards for basic message passing (send/receive), as well as higher-level communication constructs (global summation, broadcast, etc.), become essential to the development of scalable libraries that have any degree of portability. In addition to standardizing general communication primitives, it may also be advantageous to establish standards for problem-specific constructs in commonly occurring areas such as linear algebra.
The BLACS (Basic Linear Algebra Communication Subprograms)
[16, 25] is a package that
provides the same ease of use and portability for MIMD
message-passing linear algebra communication that the BLAS
[17, 18, 40]
provide
for linear algebra computation.
Therefore, we recommend that future software for dense linear algebra on
MIMD platforms consist of calls
to the BLAS for computation and calls to the BLACS for communication.
Since both packages will have been optimized for
a particular platform, good performance
should be achieved with relatively little effort. Also, since both packages
will be available on a wide variety of machines, code modifications required
to change platforms should be minimal.
This is borne out by prototype implementations of ScaLAPACK on the IBM SP-1,
the CRAY T3D, and Thinking Machines Corporation's
CM-5. Preliminary results for the
IBM SP-1 and CRAY T3D indicate that the ScaLAPACK code runs efficiently on
these machines - a 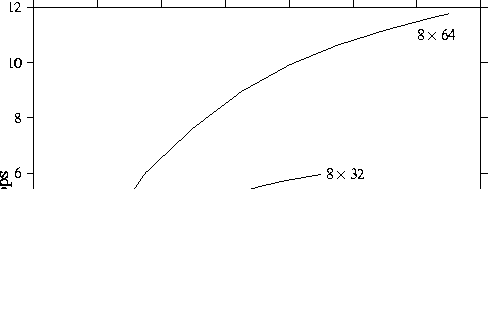 LU factorization runs at 21.4 Gflop/s
on a 256-node CRAY T3D. An
LU factorization runs at 21.4 Gflop/s
on a 256-node CRAY T3D. An ![]() LU factorization runs at
5.3 Gflop/s on a 64-node CRAY T3D, compared with 2.6 and 2.0 Gflop/s for
64-node IBM SP-1 and Intel Paragon machines, respectively.
Initial results on the CM-5, however, have been disappointing because of the
difficulty of using the vector units in message passing programs.
LU factorization runs at
5.3 Gflop/s on a 64-node CRAY T3D, compared with 2.6 and 2.0 Gflop/s for
64-node IBM SP-1 and Intel Paragon machines, respectively.
Initial results on the CM-5, however, have been disappointing because of the
difficulty of using the vector units in message passing programs.
The EISPACK, LINPACK, and LAPACK linear algebra libraries are in the public domain, and are available from netlib. For example, for more information on how to obtain LAPACK, send the following one-line email message to netlib@ornl.gov:
send index from lapack
Information for EISPACK and LINPACK can be similarly obtained. A preliminary version of the ScaLAPACK library is also available from netlib.