The philosophy of PVM has always been to keep the user interface simple and to let PVM do the hard work in order to improve the performance. This is why all sends in PVM are asynchronous and blocking. On the other hand, MPP systems usually provide efficient native communication features. PVM's goal is to use them to improve its performance while keeping its simple message-passing semantic and interface. Therefore, in PVM 3.3, the routines pvm_psend() and pvm_precv() have been added. The pvm_psend() routine combines the initialize, pack, and send steps into a single call with an orientation toward performance, while pvm_precv() combines the unpacking and the receive steps. The results in this paper clearly show that these new routines yield improved performance and can survive the comparison with the native message-passing systems.
Users who build applications for a homogeneous configuration and have only contiguous data to transmit should benefit from the pvm_psend() and pvm_precv() calls. These routines can provide extremely high performance communication, as efficient as the native communication on MPP systems.
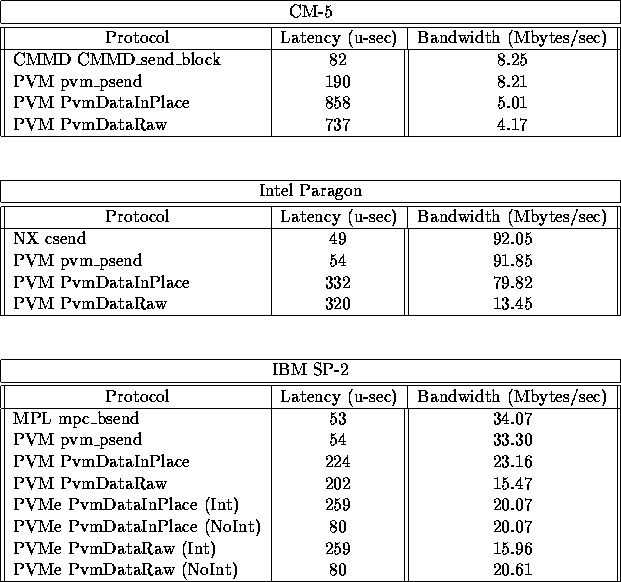
Table: Summary table of the performance results