Youngbae Kim![]()
![]() NERSC, Lawrence Berkeley National Laboratory
NERSC, Lawrence Berkeley National Laboratory
University of California
Berkeley, CA 94720, USA
youngbae@nersc.gov
-
James S. Plank![]()
![]() Department of Computer Science
Department of Computer Science
The University of Tennessee
Knoxville, TN 37996-1301, USA
plank@cs.utk.edu
-
Jack J. Dongarra![]()
![]() Mathematical Science Section
Mathematical Science Section
Oak Ridge National Laboratory
Oak Ridge, TN 37821-6367, USA
dongarra@[cs.utk.edu, msr.epm.ornl.gov]
Recently, an algorithm-based approach using diskless checkpointing has been developed to provide fault tolerance for high-performance matrix operations. With this approach, since fault tolerance is incorporated into the matrix operations, the matrix operations become resilient to any single processor failure or change with low overhead. In this paper, we present a technique called multiple checkpointing to enable the matrix operations to tolerate a certain set of multiple processor failures by adding the capacity for multiple checkpointing processors. The results on a network of workstations have shown that this technique improves not only the reliability of the computation but also the performance of checkpointing.
![]()
Introduction Due to the price and performance of uniprocessor workstations and off-the-shelf networking, networks of workstations (NOWs) have become a cost-effective parallel processing platform that is competitive with supercomputers. The popularity of NOW programming environments like PVM [10] and MPI [29] and the availability of high-performance numerical libraries like ScaLAPACK (Scalable Linear Algebra PACKage) [6] for scientific computing on NOWs show that networks of workstations are already in heavy use for scientific programming.
The major problem with programming on a NOW is the fact that it is prone to change. Idle workstations may be available for computation at one moment, but gone the next due to failure, load, or availability. We term any such event a failure. Thus, on the wish list of scientific programmers is a way to perform computation efficiently on a NOW whose components are tolerant to failure.
Recently, a fault-tolerant computing paradigm based on diskless checkpointing has been developed in the papers [16, 17, 22, 23]. The paradigm is based on checkpointing and rollback recovery using processor and memory redundancy with any reliance on disk. Its underlying idea is to adopt the N+1 parity used by Gibson to provide reliability in RAID (Redundant Array of Inexpensive Disks) [12]. The paradigm is an algorithm-based approach in which fault tolerance is especially tailored to the applications.
In this paradigm, a global checkpoint is taken and maintained in a checkpointing processor as a checksum or a parity of local checkpoints to encode the data. When a processor failure occurs, an extra idle processor replaces the failed processor and recovers its data from remaining application processors and the global checkpoint. For this paradigm, two checkpointing techniques based on parity [22, 23] or checksum and reverse computation [17], are used to incorporate fault tolerance into high-performance matrix operations. Throughout this paper, we call these techniques single checkpointing because it employs only one checkpointing processor.
In this paper, we present a new technique called multiple checkpointing. In multiple checkpointing, we extend any single checkpointing technique to tolerate a certain set of multiple processor failures simultaneously by adding the capacity for multiple checkpointing processors. The general idea of multiple checkpointing is to maintain coding information in m extra processors so that if one or more (up to m) application processors fail in the middle of computation, then they can be replaced instantly by one or more of the extra processors.
In our implementations, we have added the capacity for multiple checkpointing processors to the fault-tolerant matrix operations using checksum and reverse computation developed in [17]. The analytic and experimental results have shown that using multiple checkpointing processors improves not only the reliability of the computation but also the performance of checkpointing. In particular, our technique reaps significant benefits from multiple checkpointing with relatively less memory by checkpointing at a finer-grain interval.
In Section 2, we review first the basic concept of single checkpointing and then introduce multiple checkpointing. In Section 3, we analyze the overhead of a multiple checkpointing technique and compare against the correponding single checkpointing technique. In Section 4, we give a short description of how a multiple checkpointing technique can be incorporated in well-known algorithms in numerical linear algebra. In Section 5, we describe implementations in detail and show the performance of the implementations on a cluster of 20 Sun Sparc-5 workstations connected by a fast-switched Ethernet. In the subsequent sections, we discuss some issues raised by our technique, compare related work, draw conclusions, and suggest avenues for future work. Checkpointing and Recovery Basic Concept Our technique for checkpointing and rollback recovery adopts the idea of algorithm-based diskless checkpointing [22] and hence enables a system with fail-stop failures [31] to tolerate failures by periodically saving the entire state and rolling back to the saved state if a failure occurs.
If the program is executing on a subset of N processors called application processors, there is a subset of m idle processors. At all points in time, a consistent checkpoint is held in the N processors in memory. A checksum (floating-point addition) of the N checkpoints is held in one of m idle processor called checkpointing processor. This checksum is called the global checkpoint. If any processor fails, all live processors, including the checkpointing processor, cooperate in reversing the computations performed since the last checkpoint. Thus, the data is restored at the last checkpoint for rollback, and the failed processor's state can be reconstructed on the checkpointing processor as the checksum of the global checkpoint and the remaining N-1 processors' local checkpoints.
In the following two subsections, two recovery models are described--one for tolerating any single processor failure and the other for tolerating multiple processor failures.
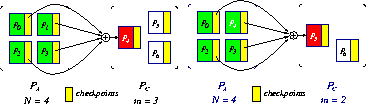
Figure 1: Single-failure recovery model: before/after a failure
This model, consisting of N application processors and m spare processors, can handle m single failures during the lifetime of the application. The program executes on N processors; there is a single checkpointing processor. Figure 1 depicts how to construct checkpoints and how to recover in the presence of a single failure. As shown, a spare processor becomes the new checkpointing processor after recovery, if one is available. The model therefore tolerates m single failures. Multiple-Failure Recovery Model A generalization of the single-failure recovery model, the multiple-failure recovery model consists of N+m processors that can tolerate up to m failures at once. Instead of having one dedicated processor for checkpointing, the entire set of application processors is divided into m groups, and one checkpointing processor is dedicated to each group. When one failure occurs in a group, the checkpointing processor in the group will replace the failed one, and the application will roll back and resume at the last checkpoint. Figure 2 shows the application processors logically configured into a two-dimensional mesh, with a checkpointing processor dedicated to each row of processors.
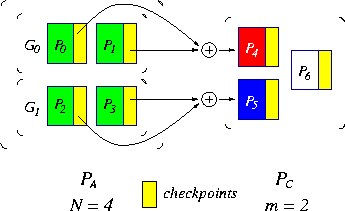
Figure 2: A multiple-failure recovery model
This model enables the algorithm to tolerate a certain set of multiple failures simultaneously, one failure for each group (e.g. each row or column of processors). This is often called the one-dimensional parity scheme [13]. Multiple Checkpointing A multiple checkpointing technique is based on the multiple-failure recovery model of using multiple checkpointing processors. It can be used together with any single checkpointing technique to tolerate multiple failures. A simple scheme for tolerating multiple failures with multiple checkpointing processors is to employ one-dimensional parity.
For the one-dimensional parity scheme, we assume that one checkpointing
processor is dedicated to each column of a ![]() processor grid.
Note that such a scheme allows the program to tolerate Q simultaneous
failures as long as failures occur in different groups,
for example, columns of processors.
With multiple checkpointing processors, each column of processors, including
its dedicated checkpointing processor, cooperates to checkpoint
its part of the matrix independently from the other columns of
processors.
Since the checkpointing and recovery can be distributed into groups of
processors (i.e., columns of processors),
the overhead of both checkpointing and recovery can be reduced.
In addition, when the checksum is used, it reduces
the possibility of overflow, underflow, and cancellation
because fewer processors are involved in each checksum.
Details of this technique can be found in [16].
Analysis of Checkpointing
In this section,
the time complexity of checkpointing matrices is analyzed.
This analysis will provide a basic formula for computing the overhead of
checkpointing and recovery in each fault-tolerant matrix operation.
processor grid.
Note that such a scheme allows the program to tolerate Q simultaneous
failures as long as failures occur in different groups,
for example, columns of processors.
With multiple checkpointing processors, each column of processors, including
its dedicated checkpointing processor, cooperates to checkpoint
its part of the matrix independently from the other columns of
processors.
Since the checkpointing and recovery can be distributed into groups of
processors (i.e., columns of processors),
the overhead of both checkpointing and recovery can be reduced.
In addition, when the checksum is used, it reduces
the possibility of overflow, underflow, and cancellation
because fewer processors are involved in each checksum.
Details of this technique can be found in [16].
Analysis of Checkpointing
In this section,
the time complexity of checkpointing matrices is analyzed.
This analysis will provide a basic formula for computing the overhead of
checkpointing and recovery in each fault-tolerant matrix operation.
Throughout this paper,
a matrix A is partitioned into square ``blocks'' of a user-specified
block size b. Then A is distributed among the processors
![]() through
through ![]() , logically reconfigured as a
, logically reconfigured as a ![]() mesh,
as in Figure 3.
A row of blocks is called a ``row block'' and a column
of blocks a ``column block.''
If there are N processors and A is an
mesh,
as in Figure 3.
A row of blocks is called a ``row block'' and a column
of blocks a ``column block.''
If there are N processors and A is an ![]() matrix, each
processor holds
matrix, each
processor holds ![]() row blocks and
row blocks and ![]() column blocks, where it is assumed that b, P, and Q divide n.
column blocks, where it is assumed that b, P, and Q divide n.
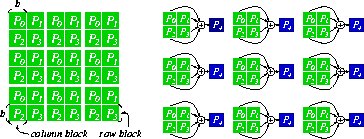
Figure 3: Data distribution and
checkpointing of a matrix with ![]() blocks
over a
blocks
over a ![]() mesh of 4 processors (using a single
checkpointing technique)
mesh of 4 processors (using a single
checkpointing technique)
Analysis of Single Checkpointing
The basic checkpointing operation works on a panel of blocks,
where each block consists of X floating-point numbers, and the
processors are logically configured in a ![]() mesh
(see Figure 3).
The processors take the checkpoint with a global addition.
This works in a spanning-tree fashion in three parts.
The checkpoint is first taken rowwise, then taken columnwise, and then
sent to the checkpointing processor
mesh
(see Figure 3).
The processors take the checkpoint with a global addition.
This works in a spanning-tree fashion in three parts.
The checkpoint is first taken rowwise, then taken columnwise, and then
sent to the checkpointing processor ![]() .
The first part therefore takes
.
The first part therefore takes ![]() steps, and the second part
takes
steps, and the second part
takes ![]() steps.
Each step consists of sending and then performing addition
on X floating-point numbers.
The third part consists of sending the X numbers to
steps.
Each step consists of sending and then performing addition
on X floating-point numbers.
The third part consists of sending the X numbers to ![]() .
We define the following terms:
.
We define the following terms:
![]() is the time for performing a floating-point addition,
is the time for performing a floating-point addition,
![]() is the startup time for sending a floating-point number,
and
is the startup time for sending a floating-point number,
and ![]() is the time for transferring a floating-point number.
is the time for transferring a floating-point number.
Details of this analysis can also be found in [16, 17].
The first part takes ![]() ,
the second part takes
,
the second part takes ![]() ,
and the third takes
,
and the third takes ![]() .
Thus, the total time to checkpoint a panel is the following:
.
Thus, the total time to checkpoint a panel is the following:
![]() .
If we assume that X is large, the
.
If we assume that X is large, the ![]() terms disappear, and
terms disappear, and
![]() can be approximated by the following equation:
can be approximated by the following equation:
![]() .
.
If we define the function
![]()
then ![]() .
For constant values of P and Q,
.
For constant values of P and Q, ![]() is a constant.
Thus,
is a constant.
Thus, ![]() is directly proportional to X.
When an entire
is directly proportional to X.
When an entire ![]() matrix needs to be checkpointed,
if we assume that m and n are large, the time complexity of
checkpointing an entire
matrix needs to be checkpointed,
if we assume that m and n are large, the time complexity of
checkpointing an entire ![]() matrix is
matrix is
![]()
We define the checkpointing rate R to
be the rate of sending a message and performing addition on
the message, measured in bytes per second.
In 64-bit floating point arithmetics, we approximate the relationship between R and ![]() as follows:
as follows:
![]()
Analysis of Multiple Checkpointing
In analyzing multiple checkpointing,
we assume that one checkpointing processor is dedicated
to checkpointing the data over a column of processors
(i.e., a ![]() processor grid).
One checkpoint is taken over each column of processors and
is then sent to the corresponding
checkpointing processor (see Figure 2).
The first part takes
processor grid).
One checkpoint is taken over each column of processors and
is then sent to the corresponding
checkpointing processor (see Figure 2).
The first part takes ![]() time,
and the second takes
time,
and the second takes ![]() time.
time.
Thus, as discussed before, the time overhead of checkpointing a panel
of X floating-point numbers can be approximated by
the following equation:
![]() .
If we also define the function
.
If we also define the function
![]()
the time overhead of checkpointing an ![]() matrix
is then given as in Eq. 2.
Fault-Tolerant Matrix Operations
We focus on three classes of matrix operations: matrix multiplication;
direct, dense factorizations; and Hessenberg reduction.
These matrix operations are at the heart of scientific computations and thus
have been implemented in ScaLAPACK.
The factorizations (Cholesky, LU, and QR) are operations for
solving systems of simultaneous linear equations and finding
least squares solutions of linear systems.
Hessenberg reduction is an operation for solving an nonsymmetric
eigenvalue problem.
Note that we choose the right-looking algorithms for the factorizations.
Their fault-tolerant implementations using the single checkpointing
technique based on checksum and reverse computation can be found
in [17].
matrix
is then given as in Eq. 2.
Fault-Tolerant Matrix Operations
We focus on three classes of matrix operations: matrix multiplication;
direct, dense factorizations; and Hessenberg reduction.
These matrix operations are at the heart of scientific computations and thus
have been implemented in ScaLAPACK.
The factorizations (Cholesky, LU, and QR) are operations for
solving systems of simultaneous linear equations and finding
least squares solutions of linear systems.
Hessenberg reduction is an operation for solving an nonsymmetric
eigenvalue problem.
Note that we choose the right-looking algorithms for the factorizations.
Their fault-tolerant implementations using the single checkpointing
technique based on checksum and reverse computation can be found
in [17].
In our implementations, we added to the matrix operations one-dimensional parity in such a way that one checkpointing processor is dedicated to checkpoint a column of processors. Implementation Results We implemented and executed these programs on a network of Sparc-5 workstations running PVM [10]. This network consists of 24 workstations, each with 96 Mbytes of RAM, connected by a switched 100 megabit Ethernet. The peak measured bandwidth in this configuration is 40 megabits per second between two random workstations. These workstations are generally allocated for undergraduate classwork, and thus are usually idle during the evening and busy executing I/O-bound and short CPU-bound jobs during the day. We ran our experiments on these machines when we could allocate them exclusively for our own use.
Each implementation was run on 20
processors, with 16 application processors logically configured
into a ![]() processor grid and 4 checkpointing processors
one for each processor column.
The block size for all implementations was set at 50, and all implementations
were developed for double-precision floating-point arithmetic.
processor grid and 4 checkpointing processors
one for each processor column.
The block size for all implementations was set at 50, and all implementations
were developed for double-precision floating-point arithmetic.
We ran two sets of tests for each instance of each problem. In the first, there is no checkpointing. In the second, the program checkpoints, but there are no failures.
Experimental results of the implementations for matrix multiplication,
LU factorization, and Hessenberg reduction are given in
Figures 4 through 6, respectively.
For comparison, each figure includes experimental results of the single
and multiple checkpointing schemes.
Each figure contains a table of experimental results and
graphs of running times, percentage checkpoint overhead, and
checkpointing rate experimentally determined.
In each table, the fifth columns represent the average checkpointing
interval in seconds, and the eighth columns represent
the average time overhead of each checkpoint.
Note that ![]() includes the initial checkpointing overhead
includes the initial checkpointing overhead ![]() and
and
![]() represents the total running time of the algorithm
without checkpointing.
K represents the checkpointing interval in iterations and is chosen
differently for each implementation to keep the checkpointing
overhead small.
Note that we use the same value of K for the multiple checkpointing technique
as the single checkpointing technique.
represents the total running time of the algorithm
without checkpointing.
K represents the checkpointing interval in iterations and is chosen
differently for each implementation to keep the checkpointing
overhead small.
Note that we use the same value of K for the multiple checkpointing technique
as the single checkpointing technique.
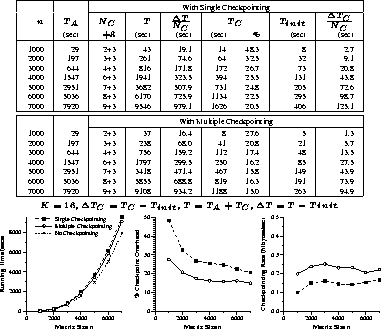
Figure 4: Matrix Multiplication: Timing Results
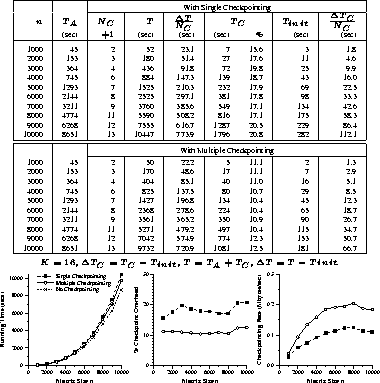
Figure 5: Right-looking LU: Timing results
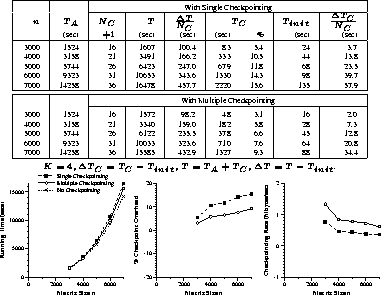
Figure 6: Hessenberg reduction: Timing results
Discussion The performance results and analyses presented in the preceding sections confirm that using multiple checkpointing processors improves considerably the performance of checkpointing and recovery for all of the fault-tolerant implementations. Thus, multiple checkpointing is more efficient and reliable by not only distributing the process of checkpointing and rollback recovery over groups of processors but also by tolerating multiple failures in one of each group of processors.
In particular, when multiple checkpointing is combined with the implementations based on checksum and reverse computation, it could reduce the checkpointing and recovery overhead without using more memory. As the performance is improved with multiple checkpointing, it could reduce checkpointing interval and hence use less memory for checkpointing. In addition, the probability of overflow, underflow, and cancellation error can be reduced. Related Work Considerable research has been carried out on algorithm-based fault tolerance for matrix operations on parallel platforms where (unlike the above platform) the computing nodes are not responsible for storage of the input and output elements [14, 27]. These methods concentrate mainly on fault-detection and, in some cases, correction.
Checkpointing on parallel and distributed systems has been studied and implemented in many literature [4, 7, 8, 9, 15, 18, 19, 24, 28]. All of this work, however, focuses on either checkpointing to disk or on process replication.
Some efforts are underway to provide programming platforms for heterogeneous computing that can adapt to changing load. These efforts can be divided into two groups: those presenting new paradigms for parallel programming that facilitate fault tolerance/migration [1, 2, 8, 11], and migration tools based on consistent checkpointing [5, 25, 30]. They cannot handle processor failures or revocation due to availability, without checkpointing to a central disk. Conclusions and Future Work We have presented a new technique for executing certain scientific computations on a changing or faulty network of workstations (NOWs). This technique employs multiple checkpointing processors to adapt the algorithm-based diskless checkpointing to the matrix operations. It also enables a computation designed to execute on N processors to run on a NOW platform where individual processors may leave and enter the NOW because of failures or load. As long as the number of processors in the NOW is greater than N, and as long as processors leave the NOW in a group, the computation can proceed efficiently.
We have implemented this technique on the core matrix operations and shown performance results on a fast network of Sparc-5 workstations. This technique has been shown to improve not only the reliability of the computation but also the performance of the checkpointing and recovery. The results indicate that our technique can also obtain lower overhead with less amount of extra memory while checkpointing at a finer checkpointing interval.
There are several more complicated schemes for configuring multiple checkpointing processors to tolerate more general sets of multiple failures. These schemes include two-dimensional parity and multi-dimensional parity [13], the Reed-Solomon coding scheme [20, , ], and Evenodd parity [3].
One possible direction of future research is to investigate how such schemes can be employed to tolerate different groups of multiple failures or a random set of multiple failures. We expect it to be challenging to implement any such fault-tolerant scheme into the target matrix operations.