 iteration steps,
where is the order of the linear system. Not only does this assume
exact arithmetic, also one does not want to do as many as iteration
steps for large systems. A major problem with iterative solution methods
is that their speed of convergence depends on certain properties of the
linear system, and these properties are often unknown in practice. This
makes it difficult to make the right selection for a method. For many very
large linear systems iterative systems are at this moment the only
possible choice; there is hardly an alternative. Therefore, it is for
engineers and scientists necessary to have a meaningful variety of iterative
methods available, and this is what Templates provides. The potential
user is guided into the world of iterative methods, and only a minimum
of linear algebra knowledge is assumed. With the information provided
in [6] the user can build high quality software at several levels
of sophistication, depending on requirements and goals.
iteration steps,
where is the order of the linear system. Not only does this assume
exact arithmetic, also one does not want to do as many as iteration
steps for large systems. A major problem with iterative solution methods
is that their speed of convergence depends on certain properties of the
linear system, and these properties are often unknown in practice. This
makes it difficult to make the right selection for a method. For many very
large linear systems iterative systems are at this moment the only
possible choice; there is hardly an alternative. Therefore, it is for
engineers and scientists necessary to have a meaningful variety of iterative
methods available, and this is what Templates provides. The potential
user is guided into the world of iterative methods, and only a minimum
of linear algebra knowledge is assumed. With the information provided
in [6] the user can build high quality software at several levels
of sophistication, depending on requirements and goals.
The starting point in Templates is the presentation of a selection of iteration methods in a very simple form, which closely follows the algorithmic descriptions in the original references. There is no monitoring of convergence behavior, and there are no precautions against numerical problems.
In this form the iteration schemes consist of one or two matrix vector
products,
a couple of inner-products and a few vector updates. The algorithms also
allow for some form of preconditioning, which means that in each step
a linear system 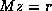 has to be solved, where
has to be solved, where 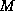 has to be specified
by the user. All these operations are pretty well understood, and it is easy
to see how the algorithms work. Although possible numerical complications are
ignored, these basic iteration Templates may be used for simple
computational experiments in order to get familiarized with the basic
iteration methods and their mutual differences. The user is given
extensive advice in the manual on how to expand the basic codes to
reliable software for practical problems.
has to be specified
by the user. All these operations are pretty well understood, and it is easy
to see how the algorithms work. Although possible numerical complications are
ignored, these basic iteration Templates may be used for simple
computational experiments in order to get familiarized with the basic
iteration methods and their mutual differences. The user is given
extensive advice in the manual on how to expand the basic codes to
reliable software for practical problems.
We believe that Templates in its present form is a good move in the process of educating and helping non-experts in understanding, and in the usage of iterative methods. Since the formulation is intentionally kept simple, it reveals the algorithmic essentials, and it shows where the major computational effort is going to be spent. The Matlab codes facilitate the user to play with the algorithms for relatively small but representative linear systems on workstations or even PC's, and help to develop some feeling for the potential usefulness of each of the methods. Together with the manual the chosen formulations provide the non-expert with a low-level entrance to the field. This approach has received approval recently in some new textbooks [40][39].
The formulations and the notations have been chosen so that differences and similarities between algorithms are easily recognized. In this respect they provide simple and easy to code algorithms, that can serve as a yardstick with which other implementations can be compared. Templates provides codes in Fortran, Matlab, and C. The codes are equivalent for each algorithm, and the only differences in outputs may be attributed to the respective computer arithmetic. This usage of Templates makes it easier to compare and to present results for iteration methods in publications. It is easier now to check results which have been obtained through these standardized codes.
As an example of how Templates is intended to function, we discuss
the algorithm for the preconditioned Conjugate
Gradient method for the iterative solution of the linear system 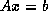 ,
with
,
with  a symmetric positive definite matrix:
a symmetric positive definite matrix:
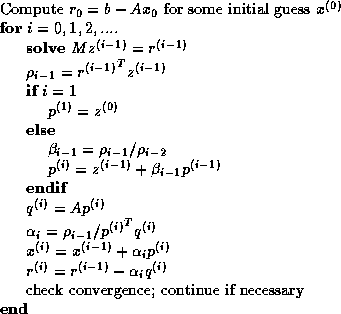
In order to make the code useful for a specific problem class, the user
has to provide a subroutine that
computes 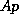 , for a given vector
, for a given vector 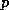 . In Templates such code is
not specified, but the user is given instructions on how to exploit
sparsity of the given matrix [6], and by well-chosen examples
it is shown how to code the matrix vector product for specific data
storage formats. The following sparse matrix storage formats are discussed
at some length:
. In Templates such code is
not specified, but the user is given instructions on how to exploit
sparsity of the given matrix [6], and by well-chosen examples
it is shown how to code the matrix vector product for specific data
storage formats. The following sparse matrix storage formats are discussed
at some length:
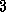 vectors: one for the floating point nonzero entries of
(val), the other two with integers (col_ind,
row_ptr).
The row_ptr vector stores the locations in the val vector that
start a row; the col_ind vector stores the column indexes of the
elements in the val vector. The matrix vector product should then
look like
vectors: one for the floating point nonzero entries of
(val), the other two with integers (col_ind,
row_ptr).
The row_ptr vector stores the locations in the val vector that
start a row; the col_ind vector stores the column indexes of the
elements in the val vector. The matrix vector product should then
look like
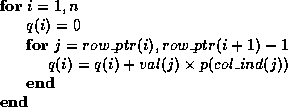
Also suggestions are supplied for coding this on parallel computers.
For some algorithms also code has to be provided that generates 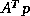 ,
and this is given much attention.
,
and this is given much attention.
Similarly, the user has to provide a subroutine that solves the
equation for given right-hand side  . In this respect is
called the preconditioner and the choice for an appropriate
preconditioner is left to the user. The main reason for this is that it
is very difficult, if not impossible, to predict what a good preconditioner
might be for a given problem of which little else is known besides the
fact that is symmetric positive definite. In [6] an
overview is given of possible choices and semi-code for the construction
of some popular preconditioners is provided, along with instructions and
examples on how to code them for certain data-storage formats.
A popular preconditioner that is often used in connection with the Conjugate
Gradient method is the Incomplete Cholesky preconditioner.
If we write
the matrix as
. In this respect is
called the preconditioner and the choice for an appropriate
preconditioner is left to the user. The main reason for this is that it
is very difficult, if not impossible, to predict what a good preconditioner
might be for a given problem of which little else is known besides the
fact that is symmetric positive definite. In [6] an
overview is given of possible choices and semi-code for the construction
of some popular preconditioners is provided, along with instructions and
examples on how to code them for certain data-storage formats.
A popular preconditioner that is often used in connection with the Conjugate
Gradient method is the Incomplete Cholesky preconditioner.
If we write
the matrix as 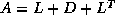 (
(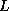 is strictly lower diagonal,
is strictly lower diagonal,  is
diagonal), then a simplified form of the preconditioner
can be written as
is
diagonal), then a simplified form of the preconditioner
can be written as 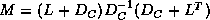 , and in [6]
formulas
are given for the computation of the elements of the diagonal matrix
, and in [6]
formulas
are given for the computation of the elements of the diagonal matrix 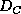 .
Since the factor is part of , the coding for the preconditioner is
not too complicated.
.
Since the factor is part of , the coding for the preconditioner is
not too complicated.
The other operations (inner-products and vector updates) in the algorithm are coded, in the Fortran codes, as BLAS operations. On most modern computers these BLAS are standard available as optimized kernels, and the user needs not to be concerned with these vector operations.
So if the user wants to have transportable code then he only needs to focus
on the matrix vector product and the preconditioner.
However, there is more that the user might want to reflect on.
In the standard
codes only a simple stopping criterion is provided, but in [6]
a lengthy discussion is provided on different possible termination
strategies and their merits.
Templates for these strategies have not yet been provided since the
better of these strategies require estimates for such quantities as
 , or even
, or even 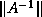 , and we do not know about convenient
algorithms for estimating these quantities (except possibly for the
symmetric positive definite case). This is in contrast with dense systems,
for which efficient estimators are available. As soon as a reliable
estimating mechanisms for these norms become known then a template can be
added.
, and we do not know about convenient
algorithms for estimating these quantities (except possibly for the
symmetric positive definite case). This is in contrast with dense systems,
for which efficient estimators are available. As soon as a reliable
estimating mechanisms for these norms become known then a template can be
added.
The situation for other methods, for instance Bi-CG, may be slightly more complicated. Of course the standard template is still simple but now the user may be facing (near) break-down situations in actual computing. The solution for this problem is quite complicated, and the average user may not be expected to incorporate this easily and is referred to more professional software at this moment. A template for a cure of the break-downs would be very nice but is not planned as yet.
Also the updating for the residual vector 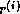 and the approximate
solution
and the approximate
solution 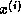 may suffer from problems due to the use of finite
precision arithmetic. This may result into a vector that
differs significantly from
may suffer from problems due to the use of finite
precision arithmetic. This may result into a vector that
differs significantly from 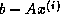 , whereas these vectors should be
equal in exact arithmetic. Recently, good and reliable strategies have
been suggested [34], and these are easily incorporated into the
present Templates.
, whereas these vectors should be
equal in exact arithmetic. Recently, good and reliable strategies have
been suggested [34], and these are easily incorporated into the
present Templates.
At the moment the linear systems templates for iterative methods form a good starting point for the user for the construction of useful software modules. It is anticipated that in future updates, templates will be added for algorithmic details, such as reliable vector updating, stopping criteria, and error monitoring. It is also conceivable that templates will be provided that help the user to analyze the convergence behavior, and to help get more insight in characteristics of the given problem. Most of these aspects are now covered in the Templates book, in the form of guidelines and examples. The Templates book [6] gives an abundance of references for more background and for all kinds of relevant details.