
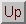


| Machine type | Shared-memory multi-vectorprocessor |
|---|---|
| Models | Cray J90, T90 |
| Operating system | UNICOS (Cray Unix variant) |
| Compilers | Fortran, C, C++, Pascal, ADA |
| Vendors information Web page | http://www.cray.com/products/systems |
| Year of introduction | J90: 1994, T90: 1995, J90se: 1997. |
System parameters:
| Model | Cray J90(se) | Cray T90 |
|---|---|---|
| Clock cycle | 10 ns | 2.2 ns |
| Theor. peak performance | ||
| Per processor | 200 Mflop/s | 1.8 Gflop/s |
| Maximal | 6.4 Gflop/s | 58 Gflop/s |
| Main memory | <= 4 GB | <= 8 GB |
| Memory bandwidth | ||
| Single proc. bandwidth | 1.6 GB/s | 24 GB/s |
| No. of processors | 4-32 | 1-32 |
Remarks:
Cray Research Inc. (CRI) has been taken over by Silicon Graphics (SGI) but for the next few years Cray will maintain separate product lines from SGI. Here we discuss the Cray-inherited vector systems.
Cray supports at this moment 3 product lines (apart from the SuperSparc-based CS6400 which is targeted to the commercial market and is not discussed in this report). Two of these are multi-headed vector processors which are discussed here. The third is the T3E, a DM-MIMD machine that will be described in the DM_MIMD section.
The Cray J90 series is the entry level model marketed by CRI announced in September 1994. The J90 series is based on CMOS technology which has a low power consumption (all J90s are air cooled) and low production costs. The machine is binary compatible with the high-end systems. It has one multiply and add vector pipe set per CPU at a clock cycle of 10 ns which results in a theoretical peak performance of 200 Mflop/s. Furthermore, a cache has been added to speed up scalar processing. It is interesting to note that the strategy of using more (four) multi-functional pipes as in the predecessor, the Y-MP EL has been left again to return to the classic two-pipe/CPU design. Recently, an enhancement of the scalar speed is available with the J90se processors where "se" stands for "scalar enhanced". The vector performance of these processors is exactly the same as that of the original J90 processors. However, the scalar performance is twice as fast. This should diminish the gap in performance on scalar code between the J90 systems and the performance of pipelined fast RISC processors as employed in high-end workstations.
The Cray T90 series is built in ECL logic and has therefore a much lower clock cycle (2.2 ns) and correspondingly faster SRAM memory. As its direct predecessor, the Cray C90, every CPU contains two vector add and multiply pipes. This gives rise to a maximum of 4 floating-point results/clock cycle/CPU equivalent to a theoretical peak performance of 1.8 Gflop/s per CPU or 58 Gflop/s for a maximal system.
The Cray T90 machines are at this moment the only ones with a memory bandwidth as seems optimal for vector processors: two operands can be loaded and one result can be stored in one cycle for each pipe set. For the T90 this meant that the relative bandwidth has to be 48 bytes/cycle/CPU. This has indeed been accomplished and observed results indicate that for the T90 the performance scales up with the clock cycle and the number of functional units (see measured performances below). For the J90 series the bandwidth is lower: 16 bytes/cycle. This is regrettably less than was available in its predecessors, Y-MP EL machines, and it might adversely affect the efficiency.
Another property that is unique for the Cray T90 systems is that they do not have a separate scalar processor but that scalar and vector code have to share the same functional units. However, a small scalar cache is added to speed up scalar calculations. The Cray J90 series has separate scalar processors. Theoretically, the absence of separate scalar processors might impair the throughput speed (Hitachi even adds an extra scalar processor in the S-3800 series to combat excessive context switching). However, in practice the drawbacks seem rather limited.
Contrary to earlier high-end Cray systems, the T90 now features compatibility with the IEEE 754 floating-point standard. Formerly, Cray-specific floating-point arithmetic was employed which could give rise to problems in data exchange with other systems and in different computational results due to the difference in arithmetic.
Measured Performances: On the T90 in
[2] a speed of 29.4 Gflop/s was
found on a 32 processor machine for the solution of an order 1000 dense
linear system and of 36.6 Gflop/s for a system of order 16384. This means that
efficiencies of 51 and 64%, respectively. However, in the latter case
Strassen's algorithm was used for the matrix multiplications involved which
gives a slightly more favourable view of the performance than when a
"standard" matrix multiplication would have been used.
For a J90 series machine with 32 processors a speed of 4.486 Gflop/s
was observed with linear system solving for an order 1000 system, which
amounts an efficiency of 70%. Also using Strassen's algorithm for a
system of order 19456 a speed of 7.6 Gflop/s was attained.