



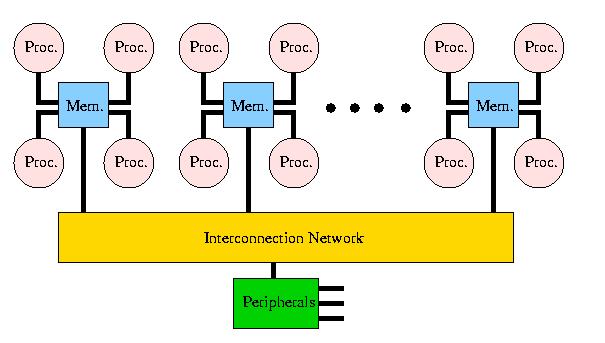
As already mentioned in the introduction, a trend can be observed to build systems that have a rather small (up to 16) number of RISC processors that are tightly integrated in a cluster, a Symmetric Multi-Processing (SMP) node. The processors in such a node are virtually always connected by a 1-stage crossbar while these clusters are connected by a less costly network. Such a system may look as depicted in Figure 6. Note that in Figure 6 all CPUs in a cluster are connected to a common part of the memory.
This is similar to the policy mentioned for large vectorprocessor
ensembles mentioned above but with the important difference that all of
the processors can access all of the address space if necessary. The
most important ways to let the SMP nodes share their memory are S-COMA
Simple Cache-Only
Memory Architecture) and ccNUMA,
which stands for Cache Coherent
Non-Uniform Memory
Access. Therefore, such systems can be considered as
SM-MIMD machines. On the other hand, because the memory is physically
distributed, it cannot be guaranteed that a data access operation
always will be satisfied within the same time. In S-COMA systems the
cache hierarchy of the local nodes is extended to the memory of the
other nodes. So, when data is required that does not reside in the
local node's memory it is retrieved from the memory of the node where
it is stored. In ccNUMA this concept is further extended in that all
memory in the system is regarded (and addressed) globally. So, a data
item may not be physically local but logically it belongs to one shared
address space. Because the data can be physically dispersed over many
nodes, the access time for different data items may well be different
which explains the term non-uniform data access. The term "Cache
Coherent" refers to the fact that for all CPUs any variable that is to
be used must have a consistent value. Therefore, is must be assured
that the caches that provide these variables are also consistent in
this respect. There are various ways to ensure that the caches of the
CPUs are coherent. One is the snoopy bus protocol in which the
caches listen in on transport of variables to any of the CPUs and
update their own copies of these variables if they have them. Another
way is the directory memory, a special part of memory which
enables to keep track of the all copies of variables and of their
validness.
Presently, no commercially available machine uses the S-COMA scheme. By
contrast, there are several popular ccNUMA systems (Bull NovaScale, HP
Superdome, and SGI Altix3000) commercially available. An important
characteristic for NUMA machines is the NUMA factor. This factor
shows the difference in latency for accessing data from a local memory location
as opposed to a non-local one. Depending on the connection structure of the
system the NUMA factor for various parts of a system can differ for part to
part: accessing of data from a neighbouring node will be faster than from a
distant node in which possibly a number of stages of a crossbar must be
traversed. So, when a NUMA factor is mentioned, this is mostly for the largest
network crosssection, i.e., the maximal distance between processors.
For all practical purposes we can classify these systems as being SM-MIMD machines also because special assisting hardware/software (such as a directory memory) has been incorporated to establish a single system image although the memory is physically distributed.