
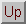


| Machine type | Processor array |
|---|---|
| Models | Gamma II 1000, Gamma II 4000 |
| Front-end | Sun of HP workstation, stand-alone for dedicated applications |
| Operating system | Internal OS transparent to the user, Unix on front-end |
| Connection structure | 2-D mesh, row- and column datapaths (see remarks) |
| Compilers | FORTRAN-PLUS (a Fortran 77 compiler with some Fortran 90 and some proprietary array extensions), C++ |
| Vendors information Web page | http://www.techcentral.com |
System parameters:
| Model | Gamma II 1000 | Gamma II 4000 |
|---|---|---|
| Clock cycle | 33 ns | 33 ns |
| No. of processors | 1024 | 4096 |
| Theor. peak performance | ||
| Per Proc. (Mflop/s) | 1.2 | 1.2 |
| 1-bit Gop/s | 30.7 | 122.8 |
| 8-bit Gop/s | 30.7 | 122.8 |
| Gflop/s (32-bit) total | 1.2 | 4.8 |
| Program memory | <= 4 MB | <= 4 MB |
| Data memory | <= 32 MB | <= 128 MB |
| Int. comm. speed | ||
| Across row, column | 120 MB/s | 480 MB/s |
| Memory to PE | 3.84 GB/s | 15.4 GB/s |
Remarks:
In November 1995 the new Gamma II models has been announced by CPP. In essence there is not much difference with its predecessor the DAP Gamma. However, the clock cycle has tripled to 33 ns with an equivalent rise in the peak performance of the systems.
The Gamma II is presented as the fourth generation of this type of machine. Indeed, the macro architecture of the systems has hardly changed since the first ICL DAP (the first generation of this system) was conceived. As in the ICL DAP in the Gamma 1000 models the 1024 processors are ordered in a 32×32 array, while the Gamma 4000 has 4096 processors arranged in a 64×64 square.
The systems are able to operate byte parallel on appropriate operands to speed up floating-point operations, however, for logical operations bit-wise operations are possible, which makes the machines quite fast in this respect. As the byte parallel code consists of separate sequences of microcode instructions, the bit processor plane and the byte processor plane are in fact independent and can work in parallel. This is also the case for I/O operations. Also character-handling can be done very efficiently. This is the reason that Gamma systems are often used for full text searches.
As in all processor-array machines, the control processor (called the Master Control Unit (MCU) in the DAP) has a separate memory to hold program instructions while the data are held in the data memory associated with each Processing Element (PE) in the processor array. So, for a Gamma 1000 with 32 MB of data memory each PE has 32 KB of data memory directly associated to it. To access data in other PE's memories these must be brought up to the data routing plane and shifted to the appropriate processor.
As already mentioned under the heading of the connection structure, there are two ways of connecting the PEs. One is the 2-D mesh that connects each element to its North-, East-, West-, and South neighbour. In addition there are row- and column data paths that enable the fast broadcast of a row or column to an entire matrix by replication. Conversely, they can be used for row or column-wise reduction of matrix objects into a column or row-vector of results from, e.g., a summing or maximum operation.
Separate I/O processors and disk systems can be attached to the Gamma directly thus not burdening the front-end machine (and the connection between front-end and DAP) with I/O operations and unnecessary data transport. One of these I/O devices is the GIOC that can transport data to the data memory at a sustained rate of 80 MB/s transposing the data to the vertical storage mode of the data memory on the fly. Also, a direct video interface is available to operate a frame buffer.
A nice (non-standard) feature of the FORTRAN-PLUS compiler is the possibility to use logical matrices as indexing objects for computational matrix objects. This enables a very compact notation for conditional execution on the processor array. In addition, recently C++ is available.
Measured Performances: In [5] the speed of matrix multiplication on various DAP models (precursors of the Gamma systems) is analyzed. The documentation states 32-bit floating-point add speed of 1.68 Gflop/s on 4096 PEs, while a 32-bit 1,024 complex FFT would attain 2.49 Gflop/s. No independent performance figures for the Gamma II systems are available.