This section provides an overview of the different types of nodes that may appear in a HeNCE program. We will first summarize their use and then delve into the details of their node programs.
The HeNCE language contains a number of different node types. Each type is represented by an icon. Figure 4 shows all of HeNCE's node types. Notice that all but one of the icons come in pairs.
The circle icon represents a sequential computation node. It calls a user-supplied subroutine when it executes. This node type represents the basic unit of parallelism in HeNCE. Sequential computation nodes may fire when all of their predecessors in the graph have fired.
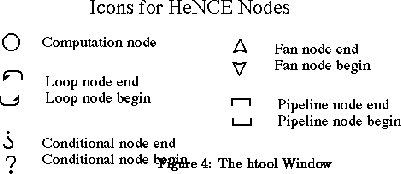
The icons that come in pairs represent ``special-purpose'' nodes. These generally define control flow within the HeNCE graph. There must always be a subgraph between a ``begin'' and an ``end'' node. The special-purpose nodes can be thought of as graph rewriting primitives. They add subgraphs to the current HeNCE graph at runtime, based upon expressions that are evaluated at runtime.
It is legal to include special-purpose nodes within the subgraph of some other special-purpose node. For example, one can place a fan inside a loop. However, the constructs must be nested. It is not legal to interleave them.
Conditional node pairs define an ``if-then'' structure. The Conditional-Begin node program contains an expression. If the expression evaluates to TRUE (meaning non-zero, following the C language convention), the subgraph between the pairs is executed. Otherwise, it is not. Note that HeNCE does not contain an ``if-then-else'' structure. In terms of graph rewriting, the subgraph is added to the graph if the expression is TRUE. Otherwise, it is replaced by an arc. See Figure 5.
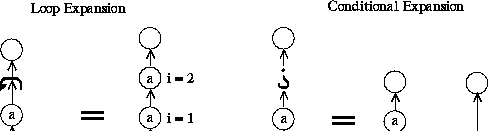
Loop node pairs define iterations much like a C ``for'' loop. The subgraph between the loop begin and the loop end node is repeated as an index variable takes on successive values. Viewed in terms of graph rewriting, the subgraph is replaced by a sequence of copies of itself. See Figure 5.
Fan node pairs create parallel structures. They replicate the subgraph between them and evaluate the replications in parallel. Figure 6 shows the effect of a Fan. The number of nodes created is determined by the Fan Begin node's program and can depend on values of runtime variables.
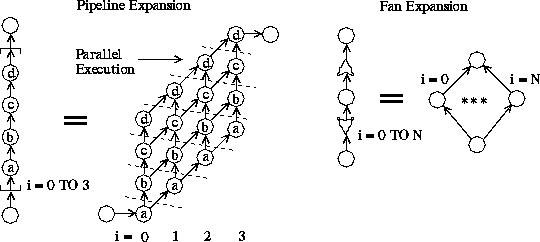
Pipe node pairs create a pipeline structure. Figure 6 also shows the effect of a pipe and delineates which nodes within the pipe can execute in parallel. The subgraph within the pipe is replicated, somewhat like a Fan node, but the dependence structure differs.
The precise action of a HeNCE node must be defined by the user. For example, a computation node executes a sequential subroutine, but the user must specify which subroutine. This is done by means of a textual description called the node program.
The syntax of node programs varies among HeNCE's node type. Computation nodes are the most complex and so will serve as the starting point. Discussion of special-purpose nodes will follow.
Computation node programs consist of three parts, but not all nodes will need all three. The purpose of the parts is described in the list below. The parts must be entered into nodes in this order.
Input declarations are of the form:
< [type] param-name [ = expression ] ;
They state that a node is to find and load the variable param-name
from its ancestors. If a type is not specified, then the
parameter is assumed to exist in ancestor nodes, and it will retain the
type declared there. If a type is specified and disagrees with the
type declared by an ancestor, then HeNCE will flag an error.
If no ancestors contain the parameter, then
it is created and initialized to expression . If there is a type but no ancestors
contain that
variable and no expression is given, then it is created and initialized to
a null value. The following are examples:
< a;
< int b = 5;
< char c[25] = "Foo";
< int d[10][15];
The first example states to load
This is a bit counter-intuitive, since writing < int b = 5;
doesn't mean that will be initialized to 5 (in other words, if
the node's parent sets
to 10, then
will be 10, and not 5).
Thus, there is an alternate input declaration form:
NEW '<' type param-name [ '=' expression ] ';'
which means that the parameter will be created anew here. Therefore,
if a node specifies NEW < int b = 5; , then Input parameters are for input only. They will not get sent to descendents. Thus, when a node declares a parameter for input, it is free to modify that parameter and those modifications will not be seen by any descendents.
If a node wants parameters to be loaded from ancestors and to be seen by descendents, then it can declare them to be Input/Output. This is done by substituting `<>' for `<' in the above syntax. Thus the following examples:
<> a;
NEW <> int b = 5;
<> char c[25] = "Foo";
<> int d[10][15];
mean the same as above, except that after their
subroutine completes, their values can be sent to descendent nodes.
Previously we stated that parameters may be initialized to expressions. Expressions may also be used to define array dimensions and subroutine arguments. An expression is defined as a combination of constants, parameters and C operators. Thus, the following are expressions:
5 a b[3][5] + c * 5.0 (d != 0) ? &d : &eIf an expression uses a parameter that is not declared, then that parameter is defaulted to be an input/output parameter. Thus, in the declaration:
<> a;
< int b = a;
the first line can be omitted: Since Circular references are not allowed. For example:
NEW < int a = b;
NEW < int b = a;
will be flagged as an error.
Arrays are declared as in C. Each dimension's specification is enclosed in square brackets. These specifications may be expressions involving other parameters. When an array is first declared, it must be with a type. This defines the size of the array, which must remain constant throughout the lifetime of the computation. If a node redeclares an array that an ancestor has already declared, then it is an error if the declarations differ in type or in the size of any dimension.
After an array has been defined, nodes may use rectangular
portions of it. Thus, nodes can split up an array to perform parallel
computations. In the simplest case, a node can specify a single
element of an array. For example, if node 1 wants to use element
of integer array
, then it can declare:
<> p[5][6];or simply use it:
foo(p[5][6]);Larger, rectangular portions of arrays can also be specified by giving the dimension's low and high values. An empty dimension will default to the entire contents of the dimension. The following are examples of specifying portions of a two-dimensional array
NEW <> int B[6][6] = A[0 : 5][10 : 15];then
NEW <> int b[6][6] = A[0 : 5][10 : 15]; NEW <> int c[6][6] = A[1 : 6][10 : 15];are perfectly legal. Each portion of
The current implementation of HeNCE has been written so that some expressions involving arrays are illegal. In particular, scalar parameters can not be set to array values. The reason for this has to do with implementation details and future versions of HeNCE should remove these restrictions. The following are illegal expressions:
NEW <> int b = c[5]; NEW <> d[1 : c[5]]; FANOUT 1 i = c[5] TO 10; foo(d[c[5]]);however, the following are legal:
NEW <> int b[5] = c[5 : 9]; foo(c[5] + c[6]);
Each node is bound to a subroutine. The subroutine call is where the arguments to the subroutine are defined, and the return value is bound. The subroutine call is a part of the node program. The syntax of the subroutine call is:
[ param = ] sub-name ( [ expression [ , expression ]* ] ) ;For example, the following are subroutine calls:
foo(); a = add(b, c); update_array(&(A[r][c]));The first example simply calls the subroutine foo. The second calls the subroutine add with the parameters
Parameters may be updated by subroutines in three ways:
If the parameter to which the return value is bound has not been declared, then it is defaulted to be output-only.
There may be some parameters which have been created or initialized by the subroutine call. These parameters can be declared as output-only after the subroutine call. Output declarations are of the form:
> type param-name ;Thus, if node 1 wants to create the parameter
NODE 1 a = foo(); > int a;A major difference between output and I/O parameters is in the assumptions about allocation: If an array is declared to be an I/O parameter, then HeNCE will allocate the space for it, and initialize it from its ancestors, if any contain the array. If it is declared as output-only, however, HeNCE assumes that the subroutine will allocate the array. Moreover, the size of the output array is determined after the subroutine call, as those determining parameters might be output-only as well.
(Note: This behavior is not fully debugged in the current
release of htool.)
For example, suppose the subroutine reads a bunch
of text from a file, and returns the length in its first parameter,
and the text in its second parameter. Then the HeNCE declaration
for
should be:
NODE 0 readtext(&len, &txt); > int len; > char txt[len];Output declarations can also be used for parameters that need to be created, but aren't used in the subroutine call. For example, suppose that the array
Array parameters cannot change size during HeNCE's execution (unless a new parameter is created using NEW). For example, if we made the following declaration:
NODE 0 NEW <> int len = 400; <> char txt[len]; readtext(&len, &txt);and
Below is a description of the special-purpose nodes and their textual syntax. As stated before, special-purpose nodes all come in pairs surrounding a subgraph. In reality, special-purpose nodes aren't nodes at all, but specify graph rewriting rules. The nature of the special-purpose node, and the values of runtime variables determine how the subgraph gets written. For example, if a conditional node evaluates to false, then the subgraph does not get included in the graph's execution.
Conditional nodes allow the user to choose whether or not subgraphs get executed, according to the runtime conditions of parameters. Like all other special-purpose nodes, conditionals come in begin/end pairs. The nodes between the pairs must form a subgraph. Otherwise, HeNCE will flag an error before performing any execution.
The syntax of conditional nodes are as follows:
'BEGINSWITCH' [ <x location> <y location> ] id '(' expression ')' ';'
'ENDSWITCH' [ <x location> <y location> ] id ';'
The expression is like any expression discussed above. It may contain
constants or parameters. All parameters are defaulted. Like
C, if the expression evaluates to 0, then it is treated as false,
and the enclosed subgraph is ignored. If it evaluates to true, then
the subgraph is executed normally.
Fanout nodes allow the user to dynamically create copies of a subgraph which will execute in parallel. Fanin nodes mark the end of the subgraph to be spawned. Their syntax is as follows:
'FANOUT' [ <x location> <y location> ] id ';'
var '=' expression 'TO' expression ';'
'FANIN' [ <x location> <y location> ] id ';'
The two expression's denote a range of values for an
var, which it treated as an output integer parameter.
For each value of var, a separate copy of the subgraph is
spawned. That copy of the subgraph may access its value of
var as an integer parameter. If the first expression evaluates
to a value less than the second, then no copys are spawned; execution
continues from the fanin node.
Loop nodes are like fanout/fanin nodes, except that the copies of the subgraph are performed serially. The syntax is like the for syntax in C:
'BEGINLOOP' [ <x location> <y location> ] id
'(' [ var '=' expression ] ';'
expression ';'
[ var '=' expression ] ')' ;
'ENDLOOP' [ <x location> <y location> ] id ';'
when the loop is first encountered, an output integer parameter (var) is created, and set to the first expression . If the middle expression
evaluates to non-zero, then the subgraph inside the loop is expanded
and executed. When it finishes, then var is updated using the
last expression , and the second expression is rechecked. If it evaluates to
zero, then execution continues from the ENDLOOP. Otherwise, the
subgraph is expanded and evaluated again. And so on.
A current restriction enforced by HeNCE is that the vars in the first and third expression must be the same. If the vars are not the same, the parser emits an error.
Pipe nodes allow control flow to be pipelined through a subgraph. The syntax is similar to fans:
'BEGINPIPE' [ <x location> <y location> ] id
var '=' expression 'TO' expression ';'
'ENDPIPE' [ <x location> <y location> ] id ';'
Again, for each value of var, a separate copy of the
subgraph is spawned. However, now, for each node in the subgraph,
there is an arc from its instance in one copy of the subgraph to
its instance in the next copy of the subgraph (i.e. from the instance
where Thus, pipes allow for a more restricted type of parallelism than fanout/fanin nodes. Specifically, if node instances need to be serialized in a certain algorithm, then the pipe construct can be used effectively.
The internal representation of arrays has two ways of storing them: As a big 1-dimensional chunk of bytes (which is what you'd get in C if you declared an array with constant sizes: e.g.int a[4][5]; gives you a pointer to a chunk of 20 ints), and as a tree of pointers (which is what you get in C otherwise - e.g.char **argv). When HeNCE allocates an array, it allocates the chunk of bytes, and then builds the pointer-tree on top of it, so either representation can be used by the programmer. Currently, HeNCE stores arrays in row major. Thus multidimensional arrays do not work as expected in FORTRAN - the programmer is advised to stick to single-dimensional arrays.
A by-product of HeNCE's storing of arrays is that one can initialize
1-d arrays from -dimensional ones, and vice-versa. For example,
the declaration:
NODE 0 NEW <> char a[10] = "abcdefghij"; NEW <> char b[2][5] = a; NEW <> char c[2][5] = "abcdefghij"; <> char a[0 : 4]; null();is perfectly legal. Here
HeNCE attempts to perform type conversion as much as possible. Therefore, in the following declaration:
NODE 0 NEW <> char a[3] = "abc" ; NEW <> int b[3] = a; NEW <> float c[3] = b; NEW <> int d = 3; NEW <> double e = d; null()