
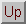


| Machine type | RISC-based distributed-memory multi-processor |
|---|---|
| Models | P9S/4--P9S/200 |
| Operating system | PARAS 9000/SS (Mach-like micro-kernel) |
| Connection structure | Multistage crossbar |
| Compilers | Fortran 77, Fortran 90, HPF, ANSI C, C++ (soon) |
System parameters:
| Model | P9S |
|---|---|
| Clock cycle | 16.6 ns |
| Theor. peak performance | |
| Per proc. (64-bit) | 60 Mflop/s |
| Maximal (64-bit) | 12 Gflop/s |
| Memory/node | <=128 MB |
| Memory (maximal) | <=25.6 GB |
| Communication bandwidth | |
| Point-to-point | 10-40 MB/s |
| Bisectional (full system) | 3.2 GB/s |
| No. of processors | 4-200 |
Remarks:
The PARAM 9000/SS is the third generation of systems that is produced by C-DAC, the Centre for Development of Advanced Computing, an institute in India that has as its mission to develop an manufacture "state-of-the-art open architecture supercomputers". This system, however, is the first one to be marketed abroad. The machine is based on the Sun SuperSparC II as a processing node. The nodes are connected by a multistage crossbar with dynamically adaptive wormhole routing which is highly useful in terms of fault-tolerance. The point-to-point bandwidth is 10 MB/s per link. With a maximum of 4 links this bandwidth can be scaled up to 40 MB/s. The bisectional bandwidth for a full 200-node system is a very respectable 3.2 GB/s. For every four compute nodes one I/O node can be configured for distributed I/O.
The amount of available software shows that the PARAM 9000/SS is not a first-generation system. Apart from Fortran 77, Fortran 90, HPF, and C++ are available and the CORE, MPI, and PVM message passing interfaces are available. There is a parallel debugger, a proprietary performance evaluation tool called AIDE, while TOTALVIEW can be delivered on request.
In addition, a library of parallel routines, PARUL, is available. This library contains PVM versions of dense linear algebra routines, eigenvalue routines, and FFTs.
Measured Performances: No measured performances of the PARAM 9000/SS are available. The performance of the computing node is rather optimistically estimated to be 60 Mflop/s for a 60 MHz processor. It is not very likely that the processing node will attain even half of this performance in practice. Even then, the system could be quite interesting in terms of price/performance.