




Timing results for the benchmark problem, using the one-dimensional code
without dynamic load balancing, are given in the tables. In
Table 9.1, results for the push time are given for
various hypercube dimensions for the Mark III and Mark IIIfp hypercubes.
Here, we define the push time as the time per particle per time step to
update the particle positions and velocities (including the interpolation to
find the forces at the particle positions) and to deposit
(interpolate) the particles' contributions to the charge and/or current
densities onto the grid. Table 9.1 shows the efficiency of the
push for runs in which the number of particles increased linearly
with the number of processors used, so that the number of particles per
processor was constant (fixed grain size). The efficiency is
defined to be 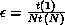 , where
, where 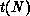 is the run time
on N processors. In the ideal situation, a code's run time on N will be
is the run time
on N processors. In the ideal situation, a code's run time on N will be
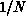 of its run time on one processor, and the efficiency is 100%. In
practice, communication between nodes and unequal processor loads leads to a
decrease in the efficiency.
of its run time on one processor, and the efficiency is 100%. In
practice, communication between nodes and unequal processor loads leads to a
decrease in the efficiency.
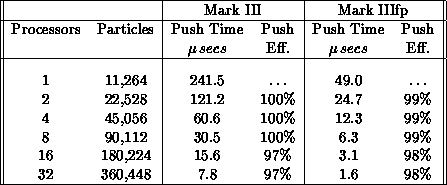
Table 9.1: Hypercube Push Efficiency for Increasing Problem Size
The Mark III Hypercube consists of up to 64 independent processors, each with four megabytes of dynamic random access memory and 128 kilobytes of static RAM. Each processor consists of two Motorola MC68020 CPUs with a MC68882 Co-processor. The newer Mark IIIfp Hypercubes have, in addition, a Weitek floating-point processor on each node. In Table 9.1, push times are given for both the Mark III processor (Motorola MC68882) and the Mark IIIfp processor (Weitek). For the Weitek runs, the entire parallel code was downloaded into the Weitek processors. The push time for the one-dimensional electrostatic code has been benchmarked on many computers [Decyk:88a]. Some of the times are given in Table 9.2; times for other computers can be found in [Decyk:88a]. For the Mark III and Mark IIIfp runs, 720,896 particles were used (11,264 per processor); for the other runs in Table 9.2, 11,264 particles were used. In all cases, the push time is the time per particle per time step to make the particle updates. It can be seen that for the push portion of the code, the 64-processor Mark IIIfp is nearly twice the speed of a one-processor CRAY X-MP and 2.6 times the speed of a CRAY 2.
We have also compared the total run time for the benchmark code for a
case with 720,896 particles and 1024 grid points run for 1000 time
steps. The total run time on the 64-node Mark IIIfp was 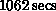 ; on a one-processor CRAY 2,
; on a one-processor CRAY 2, 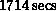 . For this
case, the 64-node Mark IIIfp was 1.6 times faster than the
CRAY 2 for the entire code. For the Mark IIIfp run,
about 10% of the total run time was spent in the initialization of the
particles, which is done sequentially.
. For this
case, the 64-node Mark IIIfp was 1.6 times faster than the
CRAY 2 for the entire code. For the Mark IIIfp run,
about 10% of the total run time was spent in the initialization of the
particles, which is done sequentially.
Benchmark times for the two-dimensional GCPIC code can be found in [Ferraro:90b].