





Figure 8.2: A Schematic Representation of a Pipeline
Broadcast for an Eight-Processor Computer. White
squares represent processors not involved in communication, and such
processors are available to perform calculations. Shaded squares
represent processors involved in communication, with the degree of
shading indicating how much of the data have arrived at any given
step. In the first six steps, those processor not yet involved in the
broadcast can continue to perform calculations.
Similarly, in steps 11 through 16, processors that are no longer involved in
communicating can perform useful work since they now have all the data
necessary to perform the next stage of the algorithm.
One of the first linear algebra algorithms implemented on the
Caltech/JPL Mark II hypercube was the multiplication of two dense
matrices, 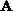 and
and 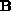 , to form the product,
, to form the product, 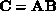 [Fox:85b]. The algorithm uses a block-oriented, linear
decomposition, which is optimal for machines with low message latency
when the subblocks are (as nearly as possible) square. Let us denote
by
[Fox:85b]. The algorithm uses a block-oriented, linear
decomposition, which is optimal for machines with low message latency
when the subblocks are (as nearly as possible) square. Let us denote
by 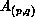 the subblock of
the subblock of 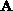 in the processor at position
in the processor at position
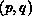 of the processor grid, with a similar designation applying to
the subblocks of
of the processor grid, with a similar designation applying to
the subblocks of 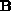 and
and  . Then, if the processor grid is
square, that is,
. Then, if the processor grid is
square, that is, 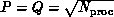 , the matrix multiplication algorithm
in block form is,
, the matrix multiplication algorithm
in block form is,
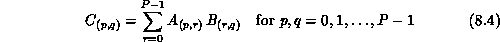
The case in which 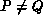 involves some extra bookkeeping, but does not
change the concurrent algorithm in any essential way.
involves some extra bookkeeping, but does not
change the concurrent algorithm in any essential way.
On the Mark II hypercube, communication cost increases with processor separation, so processors are mapped onto the processor grid using a binary Gray code scheme. Two types of communication are required at each stage of the algorithm, and both exploit the hypercube topology to minimize communication costs. Matrix subblocks are communicated to the processor above in the processor grid, and subblocks are broadcast along processor rows by a communication pipeline (Figure 8.2).
The matrix multiplication algorithm has been modified for use on the
Caltech/JPL Mark IIIfp hypercube [Hipes:89b]. The Mark II
hypercube is a homogeneous machine in the sense that there is only one
level in the memory hierarchy, that is, the local memory of each
processor. However, each processor of the Mark IIIfp hypercube has a
Weitek floating-point processor with a 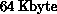 data cache. To
take full advantage of the high processing speed of the Weitek, data
transfer between local memory and the Weitek data cache must be
minimized. Since there are two levels in the memory hierarchy of each
processor (local memory and cache), the Mark IIIfp is an inhomogeneous
hypercube. The main computational task in each stage of the concurrent
algorithm is to multiply the subblocks in each processor, and for large
problems not all of the data will fit into the cache. The
multiplication is, therefore, done in inner product form on the Weitek
by further subdividing the subblocks in each processor. This
intraprocessor subblocking allows the multiplication in
each processor to be done in a number of stages, during each of which
only the data needed for that stage are explicitly loaded into the
cache.
data cache. To
take full advantage of the high processing speed of the Weitek, data
transfer between local memory and the Weitek data cache must be
minimized. Since there are two levels in the memory hierarchy of each
processor (local memory and cache), the Mark IIIfp is an inhomogeneous
hypercube. The main computational task in each stage of the concurrent
algorithm is to multiply the subblocks in each processor, and for large
problems not all of the data will fit into the cache. The
multiplication is, therefore, done in inner product form on the Weitek
by further subdividing the subblocks in each processor. This
intraprocessor subblocking allows the multiplication in
each processor to be done in a number of stages, during each of which
only the data needed for that stage are explicitly loaded into the
cache.
Independently, Cherkassky, et al. in [Cherkassky:88a], Berntsen
in [Berntsen:89a], and Aboelaze [Aboelaze:89a] improved
Fox's algorithm for dense 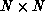 matrix multiplication, reducing the time
complexity from
matrix multiplication, reducing the time
complexity from
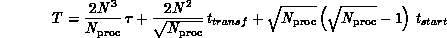
to
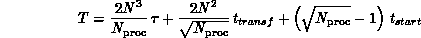
where 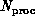 is the number of processors,
is the number of processors,  is the time for one
addition or one multiplication, and
is the time for one
addition or one multiplication, and 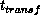 ,
, 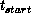 are
machine-dependent communication parameters defining bandwidth and
latency [Chrisochoides:92a]. In fact, the communication cost of
transferring w words is
are
machine-dependent communication parameters defining bandwidth and
latency [Chrisochoides:92a]. In fact, the communication cost of
transferring w words is 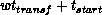
A concurrent algorithm to perform the matrix-vector product 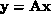 has also been implemented on the Caltech/JPL Mark II hypercube
[Fox:88a]. Again, a block-oriented, linear decomposition is used for
the matrix A. The vector x is decomposed linearly over the
processors' columns, so that all the processors in the same processor column
contain the same portion of x. Similarly, at the end of the algorithm,
the vector y is decomposed over the processor rows, so that all the
processors in the same processor row contain the same portion of y. In
block form the matrix-vector product is,
has also been implemented on the Caltech/JPL Mark II hypercube
[Fox:88a]. Again, a block-oriented, linear decomposition is used for
the matrix A. The vector x is decomposed linearly over the
processors' columns, so that all the processors in the same processor column
contain the same portion of x. Similarly, at the end of the algorithm,
the vector y is decomposed over the processor rows, so that all the
processors in the same processor row contain the same portion of y. In
block form the matrix-vector product is,
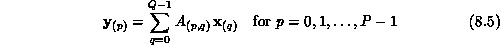
As in the matrix multiplication algorithm, the concurrent matrix-vector
product algorithm is optimal for low latency, homogeneous hypercubes if the
subblocks of 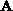 are square.
are square.