T = (N+NHALF)/RINF ==>
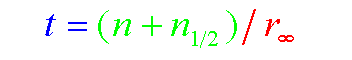
when the communication rate is given by,
R=RINF/(1+NHALF/N) = PI0*N/(1+N/NHALF) ==>
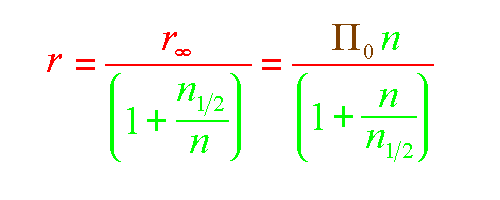
and the startup time is
T0=NHALF/RINF=1/PI0 ==>
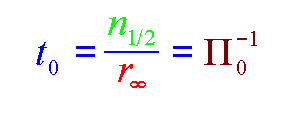
PI0 is known as the specific performance. In general, we may say that RINF characterizes the long-message performance and PI0 the short-message performance. The COMMS1 benchmark computes all four of the above parameters, RINF, NHALF, T0, and PI0, because each emphasizes a different aspect of performance. However only two of them are independent. In the case that there are different modes of transmission for messages shorter or longer than a certain length, the benchmark can read in this breakpoint and perform a separate least-squares fit for the two regions. An example is the Intel iPSC/860 which has a different message protocol for messages shorter than and longer than 100 byte.
